
后端常用工具简介
NGINX
:开源的一体式高级负载均衡器、内容缓存和网络服务器、反向代理(Advanced Load Balancer, Web Server, & Reverse Proxy)
负载均衡 LoadBalance
- 将网络请求,或者其他形式的负载“均摊”到不同的机器上。 避免集群中部分服务器压力过大,而另一些服务器比较空闲的情况。
- 通过负载均衡,可以让每台服务器获取到适合自己处理能力的负载。 在为高负载服务器分流的同时,还可以避免资源浪费,一举两得。
常见负载均衡算法工作原理
- 轮询
- 顾名思义将请求按顺序轮流地分配到后端服务器上,它均衡地对待后端的每一台服务器,而不关心服务器实际的连接数和当前的系统负载。
- 优点: 服务器请求数据相同
- 不足: 服务器压力不同,不适合根据服务器配置不同的情况
- 随机
- 通过系统的随机算法,根据后端服务器的列表大小值来随机选取其中的一台服务器进行访问。
- 由概率统计理论可以得知,随着客户端调用服务端的次数增多,其实际效果越来越接近于均分配调用量到后端的每一台服务器,也就是轮询的结果。
- 优点: 使用简单
- 缺点: 服务器压力不同,不适合根据服务器配置不同的情况
- 源地址哈希
- 源地址哈希的思想是根据获取客户端的 IP 地址,通过哈希函数计算得到的一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是客服端要访问服务器的序号。
- 采用源地址哈希法进行负载均衡,同一 IP 地址的客户端,当后端服务器列表不变时,它每次都会映射到同一台后端服务器进行访问。
- 优点: 将来自同一 IP 地址的请求,同一会话期内,转发到相同的服务器;实现会话粘滞。
- 缺点: 目标服务器宕机后,会话会丢失
- 加权轮询法
- 不同的后端服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不相同。
- 给配置高、负载低的机器配置更高的权重,让其处理更多的请;而配置低、负载高的机器,给其分配较低的权重,降低其系统负载,
- 加权轮询能很好地处理这一问题,并将请求顺序且按照权重分配到后端。
- 优点: 根据权重,调节转发服务器的请求数目
- 缺点: 使用相对复杂
- 加权随机法
- 与加权轮询法一样,加权随机法也根据后端机器的配置,系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。
- 最小连接数法
- 最小连接数算法比较灵活和智能,由于后端服务器的配置不尽相同,对于请求的处理有快有慢,
- 它是根据后端服务器当前的连接情况,动态地选取其中当前积压连接数最少的一台服务器来处理当前的请求,
- 尽可能地提高后端服务的利用效率,将负责合理地分流到每一台服务器。
- 优点: 根据服务器当前的请求处理情况,动态分配
- 缺点: 算法实现相对复杂,需要监控服务器请求连接数
“网络服务器(Web server)”可以代指硬件或软件,或者是它们协同工作的整体:
- 硬件部分,一个网络服务器是一台存储了网络服务软件以及网站的组成文件(比如,HTML 文档、图片、CSS 样式表和 JavaScript 文件)的计算机。
- 它接入到互联网并且支持与其他连接到互联网的设备进行物理数据的交互。
- 软件部分,网络服务器包括控制网络用户如何访问托管文件的几个部分,至少他要是一台 HTTP 服务器。
- 一台 HTTP 服务器是一种能够理解 URL(网络地址)和 HTTP(浏览器用来查看网页的协议)的软件。
- 通过服务器上存储的网站的域名(比如 mozilla.org)可以访问这个服务器,并且他还可以将他的内容分发给最终用户的设备。
正向代理
- 由于防火墙的原因,我们并不能直接访问谷歌,那么我们可以借助 VPN 来实现,这就是一个简单的正向代理的例子。
- 这里你能够发现,正向代理“代理”的是客户端,而且客户端是知道目标的,而目标是不知道客户端是通过 VPN 访问的。
- (正向代理: 客户端无法直接访问目标服务器,通过代理服务器去访问目标服务器。目标服务器不知道客户端是谁。)
- 正向代理,其实是”代理服务器”代理了”客户端”,去和”目标服务器”进行交互。
- 作用
- 突破访问限制
- 提高访问速度
- 隐藏客户端真实 IP
反向代理
- 在外网访问百度的时候,其实会进行一个转发,代理到内网去,这就是所谓的反向代理,
- 即反向代理“代理”的是服务器端,而且这一个过程对于客户端而言是透明的。
- (反向代理: 客户端访问代理服务器,代理服务器将请求转发给目标服务器,将结果返回。客户端不知道目标服务器是谁。)
- 反向代理,其实是”代理服务器”代理了”目标服务器”,去和”客户端”进行交互。
- 用途
- 隐藏服务器真实 IP
- 负载均衡
- 提高访问速度
- 提供安全保障
Nacos
:一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
Nacos 致力于帮助您发现、配置和管理微服务。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据及流量管理。
Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。 Nacos 是构建以“服务”为中心的现代应用架构 (例如微服务范式、云原生范式) 的服务基础设施。
使用 Nacos 简化服务发现、配置管理、服务治理及管理的解决方案,让微服务的发现、管理、共享、组合更加容易。
Spring Cloud
为开发者提供了快速构建分布式系统中一些常见模式的工具(例如,配置管理、服务发现、断路器、智能路由、微代理、控制总线、一次性令牌、全局锁、领导层选举、分布式会话、集群状态)。
分布式系统的协调导致了锅炉板模式,使用 Spring Cloud,开发者可以快速建立实现这些模式的服务和应用。
它们在任何分布式环境中都能很好地工作,包括开发人员自己的笔记本电脑、裸机数据中心和管理平台(如 Cloud Foundry)。
特点:Spring Cloud 专注于为典型的使用案例提供良好的开箱即用体验,并为其他案例提供可扩展性机制。
- 分布式/版本化的配置 Distributed/versioned configuration
- 服务注册和发现 Service registration and discovery
- 路由 Routing
- 服务对服务的调用 Service-to-service calls
- 负载平衡 Load balancing
- 断路器 Circuit Breakers
- 全局锁 Global locks
- 领导层选举和集群状态 Leadership election and cluster state
- 分布式消息传递 Distributed messaging
业务中主要用到了 Spring Cloud Gateway
该项目提供了一个库,用于在 Spring WebFlux 之上构建 API 网关。
Spring Cloud Gateway 旨在提供一种简单而有效的方式来路由到 API,并为其提供交叉关注,如:安全、监控/指标和弹性。
Spring Cloud Gateway 的特点:
建立在 Spring Framework 5、Project Reactor 和 Spring Boot 2.0 之上。 Built on Spring Framework 5, Project Reactor and Spring Boot 2.0
能够在任何请求属性上匹配路由。 Able to match routes on any request attribute.
谓词和过滤器是特定于路由的。Predicates and filters are specific to routes.
断路器集成。Circuit Breaker integration.
Spring Cloud DiscoveryClient 集成。Spring Cloud DiscoveryClient integration
易于编写谓词和过滤器。Easy to write Predicates and Filters
请求速率限制。Request Rate Limiting
路径重写。Path Rewriting
断路器: 简单理解,请求超过阈值,关闭访问;恢复到正常阈值,启动访问。
实战 Spring Cloud Gateway 之限流篇
Spring Cloud Gateway 的断路器(CircuitBreaker)功能
EMQX
是一款全球下载量超千万的大规模分布式物联网 MQTT 服务器
单集群支持 1 亿物联网设备连接,消息分发时延低于 1 毫秒。为高可靠、高性能的物联网实时数据移动、处理和集成提供动力,助力企业构建关键业务的 IoT 平台与应用。
EMQX 提供了高效可靠海量物联网设备连接,能够高性能实时移动与处理消息和事件流数据,帮助您快速构建关键业务的物联网平台与应用。
业务中使用到的 EMQX Enterprise 功能:
Kafka 数据桥接:通过内置桥接插件高效转发 MQTT 消息到 Kafka 集群,用户可以通过消费 Kafka 消息来实现实时流式数据的处理;
- 数据桥接是用来对接 EMQX 和外部数据系统的通道。外部数据系统可以是 MySQL、MongoDB 等数据库, 也可以是 Kafka,RabbitMQ 等消息中间件,或者是 HTTP 服务器等。
- 通过数据桥接,用户可以实时地将消息从 EMQX 发送到外部数据系统,或者从外部数据系统拉取数据并发送到 EMQX 的某个主题。
(看源代码的好处和作用)
为了节约成本,鉴于使用企业版只为了 kafka 数据桥接功能,于是我们在开源版本的基础上,自行编写了 kafka 桥接插件,重新编译后运行中。
具体就是当时 emqx3.3 左右的企业版,下载软件后进行了反编译,里面的 kafka 桥接插件没有加密,但之后的都加密了,依次为基础进行编写和扩展。
为了测试稳定性和性能,又魔改了https://github.com/eclipse/paho.mqtt.golang这个mqtt的客户端,进行了测试。目前运行一年多都很正常。
最近更新的 emqx 社区版是 4.3.13,在此基础中自行加入的 kafka 桥接插件也依旧正常。
虽然之前都不会 erlang,就算改完了现在再看也不会了,但大体相通,学习了写基本语法之后,加上实践,还是能做出点东西。
MQTT
(Message Queuing Telemetry Transport,消息队列遥测传输协议),是一种基于发布/订阅(publish/subscribe)模式的”轻量级”通讯协议,该协议构建于 TCP/IP 协议上,由 IBM 在 1999 年发布。
它工作在 TCP/IP 协议族上,是为硬件性能低下的远程设备以及网络状况糟糕的情况下而设计的发布/订阅型消息协议。
MQTT 最大优点在于,可以以极少的代码和有限的带宽,为连接远程设备提供实时可靠的消息服务。作为一种低开销、低带宽占用的即时通讯协议,使其在物联网、小型设备、移动应用等方面有较广泛的应用。
主要特性:
使用发布/订阅消息模式,提供一对多的消息发布,解除应用程序耦合。
对负载内容屏蔽的消息传输。
使用 TCP/IP 提供网络连接。
有三种消息发布服务质量:QoS:发布消息的服务质量,即:保证消息传递的次数
- QoS 0:最多一次传送,即“fire and forget”(只负责传送,发送过后就不管数据的传送情况)。
- QoS 1:至少一次传送(握手 2 次);PUBLISH packet 与 PUBACK packet(确认数据交付)。
- QoS 2:正好一次传送(握手 4 次);PUBLISH 、PUBREC 包用于确认收到。如果发送方没有收到 PUBREC 包,就用 DUP 标志重发消息;如果收到 PUBREC 包,就删除最初的 PUBLISH 包,存储并回复 PUBREL 包。接收方收到 PUBREL 包,就回复 PUBCOMP 包并删除所有相关状态(保证数据交付成功)。
小型传输,开销很小(固定长度的头部是 2 字节),协议交换最小化,以降低网络流量。
使用 Last Will 和 Testament 特性通知有关各方客户端异常中断的机制。
Jaeger:开源、端到端的分布式追踪。监控复杂分布式系统中的事务并排除故障
缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能 DB 就挂掉了,要是有人利用不存在的 key 频繁攻击我们的应用,这就是漏洞。
解决方法
- 采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被 这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力。
- 另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到 DB,DB 瞬时压力过重雪崩。
解决方案
- 缓存失效时的雪崩效应对底层系统的冲击非常可怕。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线 程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。
- 这里分享一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
缓存击穿
对于一些设置了过期时间的 key,如果这些 key 可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题。
- 这个和缓存雪崩的区别在于这里针对某一 key 缓存,前者则是很多 key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个 Key 有大量的并发请求过来,这些请求发现缓存过期一般都会从后端 DB 加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端 DB 压垮。
解决方案
- 1 使用互斥锁(mutex key)
- 简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去 load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如 Redis 的 SETNX 或者 Memcache 的 ADD)去 set 一个 mutex key,当操作返回成功时,再进行 load db 的操作并回设缓存;否则,就重试整个 get 缓存的方法。
- 2 “提前”使用互斥锁(mutex key):
- 在 value 内部设置 1 个超时值(timeout1), timeout1 比实际的 memcache timeout(timeout2)小。当从 cache 读取到 timeout1 发现它已经过期时候,马上延长 timeout1 并重新设置到 cache。然后再从数据库加载数据并设置到 cache 中
- 3 “永远不过期”:
- (1) 从 redis 上看,确实没有设置过期时间,这就保证了,不会出现热点 key 过期问题,也就是“物理”不过期。
- (2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在 key 对应的 value 里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期
- 4 资源保护:
- 采用 netflix 的 hystrix,可以做资源的隔离保护主线程池,如果把这个应用到缓存的构建也未尝不可。
Spring Boot
在 Spring 的基础上搭建的全新的微框架,用来简化 Spring 的搭建和开发过程。是一个简化 Spring 开发的框架。
使创建独立的(stand-alone)、基于生产级的 Spring 应用程序变得容易,你可以 “直接运行”。
我们对 Spring 平台和第三方库有自己的看法,所以你可以用最少的麻烦开始工作。大多数 Spring Boot 应用需要最小的 Spring 配置。
功能介绍
创建独立的 Spring 应用程序
直接嵌入 Tomcat、Jetty 或 Undertow(不需要部署 WAR 文件)
提供有主见的 “启动器 “依赖,以简化你的构建配置
尽可能地自动配置 Spring 和第三方库
提供生产就绪的功能,如度量、健康检查和外部化配置( metrics, health checks, and externalized configuration)
完全没有代码生成,也不需要 XML 配置
约定大于配置(推荐默认配置的思想)
开发人员仅需规定应用中不符合约定的部分
在没有规定配置的地方,采用默认配置,以力求最简配置为核心思想
Flink
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
特点:
1. 处理无界和有界数据
- 任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
数据可以被作为 无界 或者 有界 流来处理:
无界流 有定义流的开始,但没有定义流的结束。
- 它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。
- 我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。
- 处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
有界流 有定义流的开始,也有定义流的结束。
- 有界流可以在摄取所有数据后再进行计算。
- 有界流所有数据可以被排序,所以并不需要有序摄取。
- 有界流处理通常被称为批处理
Apache Flink 擅长处理无界和有界数据集 精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。
有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
- 部署应用到任意地方
Apache Flink 是一个分布式系统,它需要计算资源来执行应用程序。
Flink 集成了所有常见的集群资源管理器,例如 Hadoop YARN、 Apache Mesos 和 Kubernetes,但同时也可以作为独立集群运行。
- 运行任意规模应用
Flink 旨在任意规模上运行有状态流式应用。
因此,应用程序被并行化为可能数千个任务,这些任务分布在集群中并发执行。所以应用程序能够充分利用无尽的 CPU、内存、磁盘和网络 IO。
而且 Flink 很容易维护非常大的应用程序状态。其异步和增量的检查点算法对处理延迟产生最小的影响,同时保证精确一次状态的一致性。
- 利用内存性能
有状态的 Flink 程序针对本地状态访问进行了优化。
任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。
任务通过访问本地(通常在内存中)状态来进行所有的计算,从而产生非常低的处理延迟。
Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。
应用
- 流处理应用的基本组件
流
- (数据)流是流处理的基本要素。然而,流也拥有着多种特征。这些特征决定了流如何以及何时被处理。
- 有界 和 无界 的数据流
- 实时 和 历史记录 的数据流
状态
- 只有在每一个单独的事件上进行转换操作的应用才不需要状态,换言之,每一个具有一定复杂度的流处理应用都是有状态的。
- 任何运行基本业务逻辑的流处理应用都需要在一定时间内存储所接收的事件或中间结果,以供后续的某个时间点(例如收到下一个事件或者经过一段特定时间)进行访问并进行后续处理。
- 应用状态是 Flink 中的一等公民,Flink 提供了许多状态管理相关的特性支持:
- 多种状态基础类型
- 插件化的 State Backend
- 精确一次语义
- 超大数据量状态
- 可弹性伸缩的应用
时间
- 时间是流处理应用另一个重要的组成部分。因为事件总是在特定时间点发生,所以大多数的事件流都拥有事件本身所固有的时间语义。
- 进一步而言,许多常见的流计算都基于时间语义,例如窗口聚合、会话计算、模式检测和基于时间的 join。
- 流处理的一个重要方面是应用程序如何衡量时间,即区分事件时间(event-time)和处理时间(processing-time)。
- Flink 提供了丰富的时间语义支持:
- 事件时间模式
- Watermark 支持
- 迟到数据处理
- 处理时间模式
- 分层 API
Flink 根据抽象程度分层,提供了三种不同的 API。每一种 API 在简洁性和表达力上有着不同的侧重,并且针对不同的应用场景。
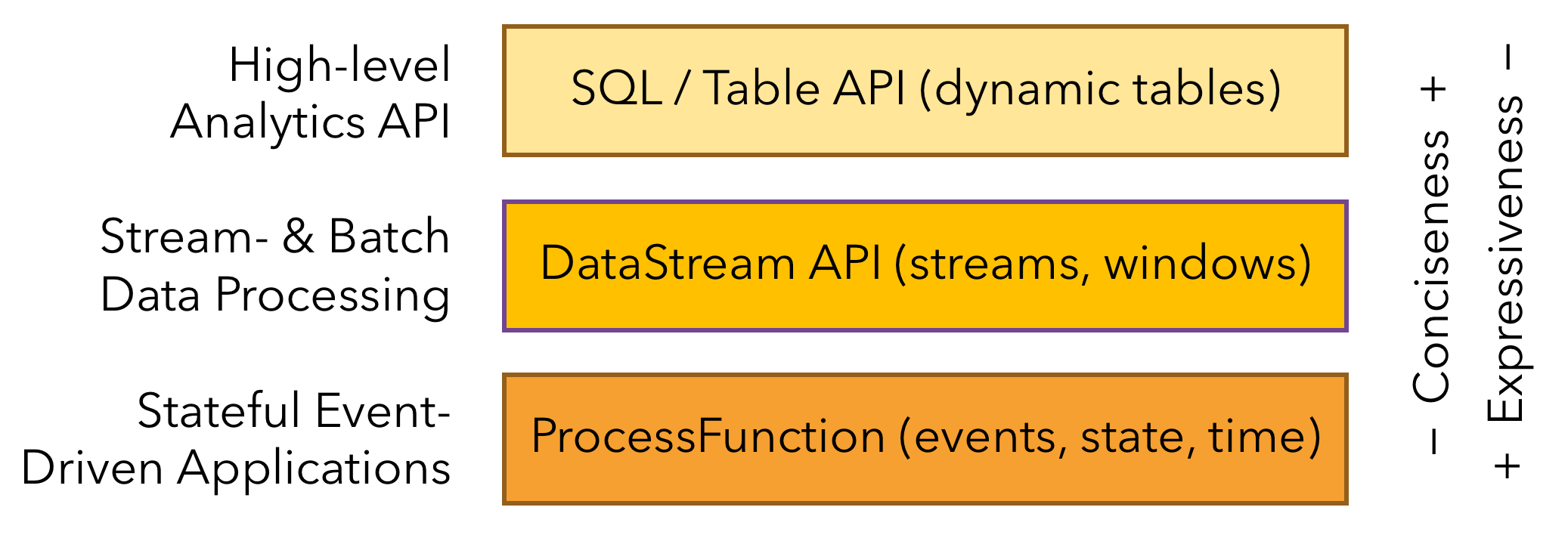
ProcessFunction
- ProcessFunction 是 Flink 所提供的最具表达力的接口。
- ProcessFunction 可以处理一或两条输入数据流中的单个事件或者归入一个特定窗口内的多个事件。
- 它提供了对于时间和状态的细粒度控制。开发者可以在其中任意地修改状态,也能够注册定时器用以在未来的某一时刻触发回调函数。
- 因此,你可以利用 ProcessFunction 实现许多有状态的事件驱动应用所需要的基于单个事件的复杂业务逻辑。
DataStream API
- DataStream API 为许多通用的流处理操作提供了处理原语。
- 这些操作包括窗口、逐条记录的转换操作,在处理事件时进行外部数据库查询等。
- DataStream API 支持 Java 和 Scala 语言,预先定义了例如 map()、reduce()、aggregate() 等函数。
- 你可以通过扩展实现预定义接口或使用 Java、Scala 的 lambda 表达式实现自定义的函数。
SQL & Table API
- Flink 支持两种关系型的 API,Table API 和 SQL。
- 这两个 API 都是批处理和流处理统一的 API,
- 这意味着在无边界的实时数据流和有边界的历史记录数据流上,关系型 API 会以相同的语义执行查询,并产生相同的结果。
- Table API 和 SQL 借助了 Apache Calcite 来进行查询的解析,校验以及优化。
- 它们可以与 DataStream 和 DataSet API 无缝集成,并支持用户自定义的标量函数,聚合函数以及表值函数。
- Flink 的关系型 API 旨在简化数据分析、数据流水线和 ETL 应用的定义。
库
- Flink 具有数个适用于常见数据处理应用场景的扩展库。这些库通常嵌入在 API 中,且并不完全独立于其它 API。它们也因此可以受益于 API 的所有特性,并与其他库集成。
- 复杂事件处理(CEP): link 的 CEP 库提供了 API,使用户能够以例如正则表达式或状态机的方式指定事件模式
- DataSet API: Flink 用于批处理应用程序的核心 API
- Gelly: 一个可扩展的图形处理和分析库
应用场景
Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。
- 事件驱动型应用
- 事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。
- 数据分析应用
- 数据分析任务需要从原始数据中提取有价值的信息和指标。传统的分析方式通常是利用批查询,或将事件记录下来并基于此有限数据集构建应用来完成。借助一些先进的流处理引擎,还可以实时地进行数据分析。
- 数据管道应用
提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。ETL 作业通常会周期性地触发,将数据从事务型数据库拷贝到分析型数据库或数据仓库。
数据管道和 ETL 作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。但数据管道是以持续流模式运行,而非周期性触发。因此它支持从一个不断生成数据的源头读取记录,并将它们以低延迟移动到终点。
Flink 架构
Flink 是一个分布式系统,需要有效分配和管理计算资源才能执行流应用程序。它集成了所有常见的集群资源管理器,例如 Hadoop YARN,但也可以设置作为独立集群甚至库运行。
Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或者多个 TaskManager。

Client 不是运行时和程序执行的一部分,而是用于准备数据流并将其发送给 JobManager。之后,客户端可以断开连接(分离模式),或保持连接来接收进程报告(附加模式)。客户端可以作为触发执行 Java/Scala 程序的一部分运行,也可以在命令行进程./bin/flink run …中运行。
可以通过多种方式启动 JobManager 和 TaskManager:直接在机器上作为 standalone 集群启动、在容器中启动、或者通过 YARN 等资源框架管理并启动。TaskManager 连接到 JobManagers,宣布自己可用,并被分配工作。
- JobManager
JobManager 具有许多与协调 Flink 应用程序的分布式执行有关的职责:它决定何时调度下一个 task(或一组 task)、对完成的 task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复等等。这个进程由三个不同的组件组成:
ResourceManager
- ResourceManager 负责 Flink 集群中的资源提供、回收、分配 - 它管理 task slots,这是 Flink 集群中资源调度的单位(请参考 TaskManagers)。Flink 为不同的环境和资源提供者(例如 YARN、Kubernetes 和 standalone 部署)实现了对应的 ResourceManager。在 standalone 设置中,ResourceManager 只能分配可用 TaskManager 的 slots,而不能自行启动新的 TaskManager。
Dispatcher
- Dispatcher 提供了一个 REST 接口,用来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 用来提供作业执行信息。
JobMaster
- JobMaster 负责管理单个 JobGraph 的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
始终至少有一个 JobManager。高可用(HA)设置中可能有多个 JobManager,其中一个始终是 leader,其他的则是 standby(请参考 高可用(HA))。
- TaskManagers
TaskManager(也称为 worker)执行作业流的 task,并且缓存和交换数据流。
必须始终至少有一个 TaskManager。在 TaskManager 中资源调度的最小单位是 task slot。TaskManager 中 task slot 的数量表示并发处理 task 的数量。请注意一个 task slot 中可以执行多个算子(请参考 Tasks 和算子链)。
Prometheus
普罗米修斯是一个开源的系统监控和警报工具包,最初是在 SoundCloud 建立的。是一套开源的监控 & 报警 & 时间序列数据库的组合。
普罗米修斯以时间序列数据的形式收集和存储其指标,也就是说,指标信息(metrics information)与记录的时间戳(timestamp)一起存储,同时还有被称为标签(labels)的可选键值对。
Prometheus 的主要优势有:
由指标名称和和键/值对标签标识的时间序列数据组成的多维数据模型。
强大的查询语言 PromQL。
不依赖分布式存储;单个服务节点具有自治能力。
时间序列数据是服务端通过 HTTP 协议主动拉取获得的。
也可以通过中间网关来推送时间序列数据。
可以通过静态配置文件或服务发现来获取监控目标。
支持多种类型的图表和仪表盘。
什么是指标 metrics?
通俗地说,度量衡是数字的测量。时间序列是指随着时间的推移记录变化。用户想要测量的东西因应用不同而不同。对于网络服务器来说,可能是请求时间,对于数据库来说,可能是活动连接数或活动查询数等等。
在理解你的应用程序为什么以某种方式工作时,指标起着重要作用。让我们假设你正在运行一个网络应用程序,并发现该程序很慢。你将需要一些信息来找出你的应用程序正在发生的事情。例如,当请求的数量很高时,应用程序会变得很慢。如果你有请求数指标,你可以发现原因,并增加服务器的数量来处理负载。
Prometheus 的组件,其中有许多组件是可选的:
Prometheus Server 作为服务端,用来存储时间序列数据。
客户端库用来检测应用程序代码。
用于支持临时任务的推送网关。
Exporter 用来监控 HAProxy,StatsD,Graphite 等特殊的监控目标,并向 Prometheus 提供标准格式的监控样本数据。
alartmanager 用来处理告警。
其他各种周边工具。
Grafana
是一个跨平台、开源的数据可视化网络应用程序平台。用户配置连接的数据源之后,Grafana 可以在网络浏览器里显示数据图表和警告。
开放和可组合的可观察性和数据可视化平台。可视化来自 Prometheus、Loki、Elasticsearch、InfluxDB、Postgres 等多个来源的指标、日志和跟踪。
实际业务中主要用于展示获取到的 k8s 的各个服务的监控埋点、tidb 的监控埋点、gitlab 自带的 prometheus 数据等,更多的是追踪服务器性能指标。
对于 dashboard 显示内容,除了自行创建外,一般也到Grafana Dashboards中去看有没有现成的,然后根据实际需求进行修改。
链路追踪
一开始使用 SkyWalking ,因为 Skywalking 使用的是 Java 动态字节码技术,字节码注入就不用再修改已经写好的代码了。但是每次项目启动都打印了很长的启动日志,有时候莫名找不到依赖,又不支持 webflux。
后来使用 Jaeger,配合 opentelemetry-java 客户端实现服务的链路追踪。不仅支持 webflux 项目,启动的打印日志很少,客户端也更小。但可以 UI 中的功能还没有 sw 那么强,但够用。
jaeger: go 编写,传输协议支持 udp/http,实现方式为拦截请求、侵入,扩展性高,性能损失中。
skywalking: java 编写, 传输协议支持 gRPC,实现方式字节码注入、无侵入,扩展性中,性能损失低。
Fluentd
是一个开源的数据收集器,用于统一的日志层。Fluentd 允许你统一数据收集和消费,以便更好地使用和理解数据
fluentd 是一个针对日志的收集、处理、转发系统。通过丰富的插件系统, 可以收集来自于各种系统或应用的日志,转化为用户指定的格式后,转发到用户所指定的日志存储系统之中。
统一日志层 Unified Logging Layer:
Fluentd 通过在两者之间提供统一的日志记录层将数据源与后端系统分离。
该层允许开发人员和数据分析师在生成日志时使用多种类型的日志。同样重要的是,它降低了“坏数据”减慢速度和误导您的组织的风险。
统一的日志记录层可让您和您的组织更好地利用数据并更快地迭代您的软件。
业务中主要用于扫描各种日志,例如服务生成的日志、微服务代码输入的日志等,存入 es 中
TiDB
是一个开源的 NewSQL 数据库,支持混合事务和分析处理工作负载。它与 MySQL 兼容,并且可以提供水平可扩展性、强一致性和高可用性。
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,
是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分布式数据库产品,
具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。
目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。
TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
五大核心特性
一键水平扩容或者缩容
- 得益于 TiDB 存储计算分离的架构的设计,可按需对计算、存储分别进行在线扩容或者缩容,扩容或者缩容过程中对应用运维人员透明。
金融级高可用
- 数据采用多副本存储,数据副本通过 Multi-Raft 协议同步事务日志,多数派写入成功事务才能提交,确保数据强一致性且少数副本发生故障时不影响数据的可用性。可按需配置副本地理位置、副本数量等策略满足不同容灾级别的要求。
实时 HTAP
- 提供行存储引擎 TiKV、列存储引擎 TiFlash 两款存储引擎,TiFlash 通过 Multi-Raft Learner 协议实时从 TiKV 复制数据,确保行存储引擎 TiKV 和列存储引擎 TiFlash 之间的数据强一致。TiKV、TiFlash 可按需部署在不同的机器,解决 HTAP 资源隔离的问题。
云原生的分布式数据库
- 专为云而设计的分布式数据库,通过 TiDB Operator 可在公有云、私有云、混合云中实现部署工具化、自动化。
兼容 MySQL 5.7 协议和 MySQL 生态
- 兼容 MySQL 5.7 协议、MySQL 常用的功能、MySQL 生态,应用无需或者修改少量代码即可从 MySQL 迁移到 TiDB。提供丰富的数据迁移工具帮助应用便捷完成数据迁移。
四大核心应用场景
对数据一致性及高可靠、系统高可用、可扩展性、容灾要求较高的金融行业属性的场景
对存储容量、可扩展性、并发要求较高的海量数据及高并发的 OLTP 场景
Real-time HTAP 场景
数据汇聚、二次加工处理的场景
TiDB 整体架构
在内核设计上,TiDB 分布式数据库将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的 TiDB 系统。
TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。
存储节点
- TiKV Server:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
- TiFlash:TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
与传统的单机数据库相比,TiDB 具有以下优势:
纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容
支持 SQL,对外暴露 MySQL 的网络协议,并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL
默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明
支持 ACID 事务,对于一些有强一致需求的场景友好,例如:银行转账
具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景
TiDB 数据库的存储
介绍 TiKV 的一些设计思想和关键概念。
Key-Value Pairs(键值对)
- 作为保存数据的系统,首先要决定的是数据的存储模型,也就是数据以什么样的形式保存下来。TiKV 的选择是 Key-Value 模型,并且提供有序遍历方法。
- TiKV 数据存储的两个关键点:
- 这是一个巨大的 Map(可以类比一下 C++ 的 std::map),也就是存储的是 Key-Value Pairs(键值对)
- 这个 Map 中的 Key-Value pair 按照 Key 的二进制顺序有序,也就是可以 Seek 到某一个 Key 的位置,然后不断地调用 Next 方法以递增的顺序获取比这个 Key 大的 Key-Value。
本地存储 (RocksDB)
- 任何持久化的存储引擎,数据终归要保存在磁盘上,TiKV 也不例外。但是 TiKV 没有选择直接向磁盘上写数据,而是把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责。这个选择的原因是开发一个单机存储引擎工作量很大,特别是要做一个高性能的单机引擎,需要做各种细致的优化,而 RocksDB 是由 Facebook 开源的一个非常优秀的单机 KV 存储引擎,可以满足 TiKV 对单机引擎的各种要求。这里可以简单的认为 RocksDB 是一个单机的持久化 Key-Value Map。
- RocksDB 是用于键值数据的高性能嵌入式数据库。它是 Google 的 LevelDB 的一个分支,经过优化,可以利用许多 CPU 内核,并有效利用快速存储(例如固态驱动器)来处理输入/输出受限的工作负载。它基于日志结构的合并树(LSM-tree)数据结构。它是用 C ++编写的,并为 C ++,C 和 Java 提供了正式的语言绑定。
Raft 协议
- 接下来 TiKV 的实现面临一件更难的事情:如何保证单机失效的情况下,数据不丢失,不出错?
- 简单来说,需要想办法把数据复制到多台机器上,这样一台机器无法服务了,其他的机器上的副本还能提供服务;复杂来说,还需要这个数据复制方案是可靠和高效的,并且能处理副本失效的情况。TiKV 选择了 Raft 算法。Raft 是一个一致性协议,本文只会对 Raft 做一个简要的介绍,细节问题可以参考它的论文。Raft 提供几个重要的功能:
- Leader(主副本)选举
- 成员变更(如添加副本、删除副本、转移 Leader 等操作)
- 日志复制
- TiKV 利用 Raft 来做数据复制,每个数据变更都会落地为一条 Raft 日志,通过 Raft 的日志复制功能,将数据安全可靠地同步到复制组的每一个节点中。不过在实际写入中,根据 Raft 的协议,只需要同步复制到多数节点,即可安全地认为数据写入成功。
- 总结一下,通过单机的 RocksDB,TiKV 可以将数据快速地存储在磁盘上;通过 Raft,将数据复制到多台机器上,以防单机失效。数据的写入是通过 Raft 这一层的接口写入,而不是直接写 RocksDB。通过实现 Raft,TiKV 变成了一个分布式的 Key-Value 存储,少数几台机器宕机也能通过原生的 Raft 协议自动把副本补全,可以做到对业务无感知。
Region
- 首先,为了便于理解,在此节,假设所有的数据都只有一个副本。前面提到,TiKV 可以看做是一个巨大的有序的 KV Map,那么为了实现存储的水平扩展,数据将被分散在多台机器上。对于一个 KV 系统,将数据分散在多台机器上有两种比较典型的方案:
- Hash:按照 Key 做 Hash,根据 Hash 值选择对应的存储节点。
- Range:按照 Key 分 Range,某一段连续的 Key 都保存在一个存储节点上。
- TiKV 选择了第二种方式,将整个 Key-Value 空间分成很多段,每一段是一系列连续的 Key,将每一段叫做一个 Region,并且会尽量保持每个 Region 中保存的数据不超过一定的大小,目前在 TiKV 中默认是 96MB。每一个 Region 都可以用 [StartKey,EndKey) 这样一个左闭右开区间来描述。
- 将数据划分成 Region 后,TiKV 将会做两件重要的事情:
- 以 Region 为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上服务的 Region 数量差不多。
- 以 Region 为单位做 Raft 的复制和成员管理。
- 以 Region 为单位做数据的分散和复制,TiKV 就成为了一个分布式的具备一定容灾能力的 KeyValue 系统,不用再担心数据存不下,或者是磁盘故障丢失数据的问题。
MVCC
- 很多数据库都会实现多版本并发控制 (MVCC),TiKV 也不例外。设想这样的场景:两个客户端同时去修改一个 Key 的 Value,如果没有数据的多版本控制,就需要对数据上锁,在分布式场景下,可能会带来性能以及死锁问题。TiKV 的 MVCC 实现是通过在 Key 后面添加版本号来实现
- 注意,对于同一个 Key 的多个版本,版本号较大的会被放在前面,版本号小的会被放在后面(见 Key-Value 一节,Key 是有序的排列),这样当用户通过一个 Key + Version 来获取 Value 的时候,可以通过 Key 和 Version 构造出 MVCC 的 Key,也就是 Key_Version。然后可以直接通过 RocksDB 的 SeekPrefix(Key_Version) API,定位到第一个大于等于这个 Key_Version 的位置。
分布式 ACID 事务
- TiKV 的事务采用的是 Google 在 BigTable 中使用的事务模型:Percolator ,TiKV 根据这篇论文实现,并做了大量的优化。
- TiDB 支持分布式事务,提供乐观事务与悲观事务两种事务模式。TiDB 3.0.8 及以后版本,TiDB 默认采用悲观事务模式。
- 简单的讲,
乐观事务模型就是直接提交,遇到冲突就回滚,悲观事务模型就是在真正提交事务前,先尝试对需要修改的资源上锁,只有在确保事务一定能够执行成功后,才开始提交。
- 简单的讲,
- 对于乐观事务模型来说,比较适合冲突率不高的场景,因为直接提交大概率会成功,冲突是小概率事件,但是一旦遇到事务冲突,回滚的代价会比较大。
- 悲观事务的好处是对于冲突率高的场景,提前上锁的代价小于事后回滚的代价,而且还能以比较低的代价解决多个并发事务互相冲突导致谁也成功不了的场景。不过悲观事务在冲突率不高的场景并没有乐观事务处理高效。
- 从应用端实现的复杂度而言,悲观事务更直观,更容易实现。而乐观事务需要复杂的应用端重试机制来保证。
TiCDC 简介
TiCDC 是一款 TiDB 增量数据同步工具,通过拉取上游 TiKV 的数据变更日志,TiCDC 可以将数据解析为有序的行级变更数据输出到下游。
TiCDC 适用场景
数据库灾备:TiCDC 可以用于同构数据库之间的灾备场景,能够在灾难发生时保证主备集群数据的最终一致性,目前该场景仅支持 TiDB 作为主备集群。
数据集成:TiCDC 提供 TiCDC Canal-JSON Protocol,支持其他系统订阅数据变更,能够为监控、缓存、全文索引、数据分析、异构数据库的主从复制等场景提供数据源。
TiCDC 的同步功能
sink 支持:目前 TiCDC sink 模块支持同步数据到以下下游:
- MySQL 协议兼容的数据库,提供最终一致性支持。
- 以 TiCDC Open Protocol 输出到 Kafka,可实现行级别有序、最终一致性或严格事务一致性三种一致性保证。
MySQL sink
- TiCDC 不拆分单表事务,保证单表事务的原子性。
- TiCDC 不保证下游事务的执行顺序和上游完全一致。
- TiCDC 以表为单位拆分跨表事务,不保证跨表事务的原子性。
- TiCDC 保证单行的更新与上游更新顺序一致。
Kafka sink
- TiCDC 提供不同的数据分发策略,可以按照表、主键或 ts 等策略分发数据到不同 Kafka partition。
- 不同分发策略下 consumer 的不同实现方式,可以实现不同级别的一致性,包括行级别有序、最终一致性或跨表事务一致性。
- TiCDC 没有提供 Kafka 消费端实现,只提供了 TiCDC 开放数据协议,用户可以依据该协议实现 Kafka 数据的消费端。
Split Region
在 TiDB 中新建一个表后,默认会单独切分出 1 个 Region 来存储这个表的数据,这个默认行为由配置文件中的 split-table 控制。当这个 Region 中的数据超过默认 Region 大小限制后,这个 Region 会开始分裂成 2 个 Region。
上述情况中,如果在新建的表上发生大批量写入,则会造成热点,因为开始只有一个 Region,所有的写请求都发生在该 Region 所在的那台 TiKV 上。
为解决上述场景中的热点问题,TiDB 引入了预切分 Region 的功能,即可以根据指定的参数,预先为某个表切分出多个 Region,并打散到各个 TiKV 上去。
使用 br 备份还原 tidb 数据
没有在 k8s 内安装 tidb 是因为实践过,启动的负载太重,特别慢,特别吃性能。tidb 启动之前得 k8s 先启动,依赖性很高,也不利于操作。
Flink job 读取 tikv 数据变更
一开始的读取 tikv 异动数据是通过 ticdc 的 kafka sink,发送到 kafka,再在 flink 中使用 kafka connector 接收变更,进行数据异动的处理,例如修改同步到宽表、es 等。
但 ticdc 通过 kafka sink 到 kafka,flink 再订阅 kafka 消息的处理不好控制,通过分析 tikv 客户端源码以及相关信息得知,可以通过 tikv-client 获取到数据异动,就像 ticdc 介绍那样,
它是拉取上游 TiKV 的数据变更日志,TiCDC 可以将数据解析为有序的行级变更数据输出到下游。所以后来改为使用 tikv 的 client-java 通过 gRPC 直接获取到 tikv 中数据变动 cdc,再使用
flink-connector-tidb-cdc 直接在 Flink 中进行数据接收及处理,省去了中间环节。
flink 文档中的 connector 没有列示全,如果没找到可以先直接搜索,然后再考虑造轮子。flink-cdc-connectors中除了 tidb-cdc 外,还有 mongodb-cdc、 mysql-cdc 等
当时使用的 tikv 的 client-java 是 3.2 版本,有一个严重的 bug 就是在 tikv 的 region split 的时候,无法正常使用。因为该 client 还是订阅的分裂前的 region,但分裂后产生的是多个新的 region,且删除了旧的 region,所以无法正常使用。所以就自行修改了该 client-java 的源代码,在出现 region split 的时候,重新读取分裂后的 region 而不是之前的。
Elasticsearch
是一个分布式的免费开源搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。
Elasticsearch 以其简单的 REST 风格 API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件;
Elastic Stack 是一套适用于数据采集、扩充、存储、分析和可视化的免费开源工具。
人们通常将 Elastic Stack 称为 ELK Stack(代指 Elasticsearch、Logstash 和 Kibana),
目前 Elastic Stack 包括一系列丰富的轻量型数据采集代理,这些代理统称为 Beats,可用来向 Elasticsearch 发送数据。
Elasticsearch 的用途
应用程序搜索
网站搜索
企业搜索
日志处理和分析
基础设施指标和容器监测
应用程序性能监测
地理空间数据分析和可视化
安全分析
业务分析
Elasticsearch 的工作原理
原始数据会从多个来源(包括日志、系统指标和网络应用程序)输入到 Elasticsearch 中。
数据采集指在 Elasticsearch 中进行索引之前解析、标准化并充实这些原始数据的过程。
这些数据在 Elasticsearch 中索引完成之后,用户便可针对他们的数据运行复杂的查询,并使用聚合来检索自身数据的复杂汇总。
- 在 Kibana 中,用户可以基于自己的数据创建强大的可视化,分享仪表板,并对 Elastic Stack 进行管理。
Elasticsearch 索引是什么?
Elasticsearch 索引指相互关联的文档集合。Elasticsearch 会以 JSON 文档的形式存储数据。
- 每个文档都会在一组键(字段或属性的名称)和它们对应的值(字符串、数字、布尔值、日期、数值组、地理位置或其他类型的数据)之间建立联系。
Elasticsearch 使用的是一种名为倒排索引的数据结构,这一结构的设计可以允许十分快速地进行全文本搜索。
- 倒排索引会列出在所有文档中出现的每个特有词汇,并且可以找到包含每个词汇的全部文档。
在索引过程中,Elasticsearch 会存储文档并构建倒排索引,这样用户便可以近实时地对文档数据进行搜索。
- 索引过程是在索引 API 中启动的,通过此 API 您既可向特定索引中添加 JSON 文档,也可更改特定索引中的 JSON 文档。
Kibana 的用途是什么?
是一个免费且开放的用户界面,能够让您对 Elasticsearch 数据进行可视化,并让您在 Elastic Stack 中进行导航。您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。
Kibana 是一款适用于 Elasticsearch 的数据可视化和管理工具,可以提供实时的直方图、线形图、饼状图和地图。Kibana 同时还包括诸如 Canvas 和 Elastic Maps 等高级应用程序;Canvas 允许用户基于自身数据创建定制的动态信息图表,而 Elastic Maps 则可用来对地理空间数据进行可视化。
创建索引模式(management-> stack management ->Kibana 索引模式)更方便日志分类
索引管理 management-> stack management ->数据 索引管理)查看索引信息、状态、映射等
开发-> 控制台 使用 elasticsearch DSL 查询数据、修改配置等
analytics -> discover 查看日志详细数据
Logstash 的用途是什么?
Logstash 是 Elastic Stack 的核心产品之一,可用来对数据进行聚合和处理,并将数据发送到 Elasticsearch。
Logstash 是一个开源的服务器端数据处理管道,允许您在将数据索引到 Elasticsearch 之前同时从多个来源采集数据,并对数据进行充实和转换。
为何使用 Elasticsearch?
Elasticsearch 很快。 由于 Elasticsearch 是在 Lucene 基础上构建而成的,所以在全文本搜索方面表现十分出色。
Elasticsearch 具有分布式的本质特征。Elasticsearch 中存储的文档分布在不同的容器中,这些容器称为分片,可以进行复制以提供数据冗余副本,以防发生硬件故障。
Elasticsearch 包含一系列广泛的功能。除了速度、可扩展性和弹性等优势以外,Elasticsearch 还有大量强大的内置功能(例如数据汇总和索引生命周期管理),可以方便用户更加高效地存储和搜索数据。
Elastic Stack 简化了数据采集、可视化和报告过程。 通过与 Beats 和 Logstash 进行集成,用户能够在向 Elasticsearch 中索引数据之前轻松地处理数据。同时,Kibana 不仅可针对 Elasticsearch 数据提供实时可视化,同时还提供 UI 以便用户快速访问应用程序性能监测 (APM)、日志和基础设施指标等数据。
倒排索引
倒排索引也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。 通过倒排索引,可以快速定位单词所在的文档列表以及该词在文档中的位置,词频等信息。供信息分析使用。
倒排索引存储信息:
| 信息名称 | 描述 |
|---|---|
| ttf | 全称:total term frequency, 表示检索词在所有文档中出现的总次数 |
| df | 全称:document frequency, 表示包含检索词的文档总数 |
| tf | 全称:term frequency, 表示检索词在文档中出现的次数 |
| docid | 全称:document id, 是文档在引擎中的唯一标识,可以通过docid获取到原文档的其他信息。 |
| fieldmap | 全称:field map, 用于记录包含检索词的field信息 |
| section 信息 | 用户可以为某些文档分段,然后为每一段添加附属信息。该信息可以在检索时取出,供后续处理使用 |
| position | 用于记录检索词在文档中的位置信息 |
| positionpayload | 全称:position payload, 用户可以为文档不同位置设置payload信息,并可以在检索时取出,供后续处理用 |
| docpayload | 全称:document payload, 用户可以为某些文档添加附属信息,并可以在检索时取出,供后续处理使用 |
| termpayload | 全称:term payload, 用户可以为某些词添加附属信息,并可以在检索时取出,供后续处理使用 |
倒排索引的基本结构:
| 结构名称 | 描述 |
|---|---|
| dictionary | 词典, 存储检索词和倒排链的映射信息。引擎可以通过词典查找检索词对应的倒排信息位置 |
| doclist | 全称:document list,存储包含检索词的文档信息 |
| positionlist | 全称:position list,存储每一篇文档中检索词所在的位置信息 |
| truncatelist | 全称:truncate list(截断链),用于提高引擎性能,根据用户的配置,将一些优质文档单独建倒排索引,以提高检索性能 |
| bitmap | 用于提高引擎性能,根据用户的配置,将一些倒排结构采用bitmap方式存储,以减少倒排所占空间,提高检索性能 |
倒排索引检索的基本流程:
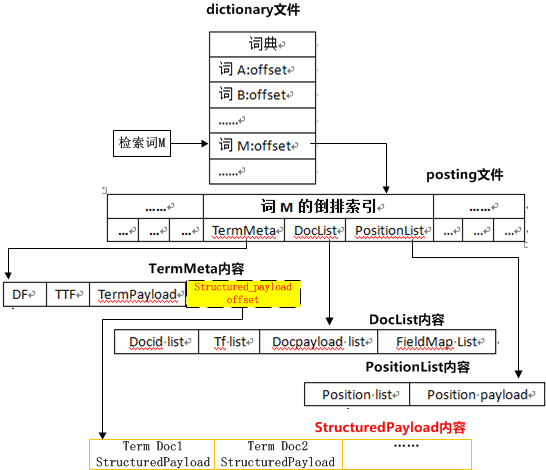
当用户查询单词 M 的倒排索引时,
首先引擎会查询词典文件,找到索引词在倒排索引文件(posting 文件)的起始位置。
随后引擎通过解析倒排链,获取词 M 存储在倒排链的三部分信息:TermMeta,DocList, PositionList。
- TermMeta 存储的是对索引词的基本描述,主要包括词的 df、ttf、termpayload 信息。
- DocList 包含索引词的文档信息列表,文档信息包括:DocumentId,文档中的检索词频(tf), docpayload, 包含检索词的 field 信息(termfield)。
- PositionList 是检索词在文档中的位置信息列表,主要包括检索词在文档中的具体位置(position)和 positionpayload 信息。

wiki
倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。
有两种不同的反向索引形式:
一条记录的水平反向索引(或者反向档案索引)包含每个引用单词的文档的列表。
一个单词的水平反向索引(或者完全反向索引)又包含每个单词在一个文档中的位置。
后者的形式提供了更多的兼容性(比如短语搜索),但是需要更多的时间和空间来创建。
应用
反向索引数据结构是典型的搜索引擎检索算法重要的部分。
一个搜索引擎执行的目标就是优化查询的速度:找到某个单词在文档中出现的地方。
- 以前,正向索引开发出来用来存储每个文档的单词的列表,接着掉头来开发了一种反向索引。
- 正向索引的查询往往满足每个文档有序频繁的全文查询和每个单词在校验文档中的验证这样的查询。
实际上,时间、内存、处理器等等资源的限制,技术上正向索引是不能实现的。
为了替代正向索引的每个文档的单词列表,能列出每个查询的单词所有所在文档的列表的反向索引数据结构开发了出来。
随着反向索引的创建,如今的查询能通过立即的单词标示迅速获取结果(经过随机存储)。随机存储也通常被认为快于顺序存储。
本文介绍阿里云 Elasticsearch 服务使用过程中遇到的常用名词的基本概念和简要描述。
集群(cluster)
- 一个 Elasticsearch 集群由一个或多个 Elasticsearch 节点组成,所有节点共同存储数据。每个集群都应有一个唯一的集群名(ClusterName),同一环境内如果存在同名集群,可能会出现不可知异常。
节点(node)
一个节点是集群中的一个服务器,用来存储数据并参与集群的索引和搜索。一个集群可以拥有多个节点,每个节点可以扮演不同的角色:
- 数据节点:存储索引数据的节点,主要对文档进行增删改查、聚合等操作。
- 专有主节点:对集群进行操作,例如创建或删除索引,跟踪哪些节点是集群的一部分,并决定哪些分片分配给相关的节点。稳定的主节点对集群的健康非常重要,默认情况下集群中的任一节点都可能被选为主节点。
- 协调节点:分担数据节点的 CPU 开销,从而提高处理性能和服务稳定性。
索引(index)
一个索引是一个拥有一些相似特征的文档的集合,相当于关系型数据库中的一个数据库。例如,您可以拥有一个客户数据的索引,一个商品目录的索引,以及一个订单数据的索引。
一个索引通常使用一个名称(所有字母必须小写)来标识,当针对这个索引的文档执行索引、搜索、更新和删除操作的时候,这个名称被用来指向索引。
类型(type)
一个类型通常是一个索引的一个逻辑分类或分区,允许在一个索引下存储不同类型的文档,相当于关系型数据库中的一张表,例如用户类型、博客类型等。
由于 6.x 以后的 Elasticsearch 版本已经不支持在一个索引下创建多个类型,因此类型概念在后续版本中不再被提及。
- Elasticsearch 5.x 允许在一个索引下存储不同类型的文档,
- Elasticsearch 6.x 在一个索引下只允许一个类型,
- Elasticsearch 7.x 索引类型命名只允许
_doc,详情请参见 Elasticsearch 官方文档。
- Elasticsearch 7.x 索引类型命名只允许
文档(document)
一个文档是可以被索引的基本信息单元,相当于关系型数据库中的一行数据。例如,您可以为一个客户创建一个文档,或者为一个商品创建一个文档。
文档可以用 JSON 格式来表示。
在一个索引中,您可以存储任意多的文档,且文档必须被索引。
字段(field)
- field 是组成文档的最小单位,相当于关系型数据库中的一列数据。
映射(mapping)
- mapping 用来定义一个文档以及其所包含的字段如何被存储和索引,相当于关系型数据库中的 Schema,例如在 mapping 中定义字段的名称和类型,以及所使用的分词器。
Elasticsearch 与关系型数据库的映射关系如下表所示:
| Elasticsearch | 关系型数据库 |
|---|---|
| 索引(index) | 数据库(Database) |
| 文档类型(type) | 表(Table) |
| 文档(document) | 一行数据(Row) |
| 字段(field) | 一列数据(Column) |
| 映射(mapping | ) 数据库的组织和结构(Schema) |
分片(shards)
shards 代表索引分片,Elasticsearch 可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上,构成分布式搜索。
分片的数量只能在索引创建前指定,并且索引创建后不能更改。
副本(replicas)
replicas 是索引的备份,Elasticsearch 可以设置多个副本。写操作会先在主分片上完成,然后分发到副本分片上。因为索引的主分片和副本分片都可以对外提供查询服务,所以副本能够提升系统的高可用性和搜索时的并发性能。但如果副本太多,也会增加写操作时数据同步的负担。
Elasticsearch 7.0 以下版本默认为一个索引创建 5 个主分片,并分别为每个主分片创建 1 个副本分片,7.0 及以上版本默认为一个索引创建 1 个主分片和 1 个副本分片。两者区别如下:
| 分片类型 | 支持处理的请求 | 数量是否可修改 | 其他说明 |
|---|---|---|---|
| 主分片 | 支持处理查询和索引请求。 | 在创建索引时设定,设定后不可更改。 | 索引内任意一个文档都存储在一个主分片中,所以主分片的数量决定着索引能够保存的最大数据量。注意 主分片不是越多越好,因为主分片越多,Elasticsearch 性能开销也会越大。 |
| 副本分片 | 支持处理查询请求,不支持处理索引请求。 | 可在任何时候添加或删除副本分片。 | 副本分片对搜索性能非常重要,主要体现在以下两个方面:提高系统的容错性能,当某个节点某个分片损坏或丢失时可以从副本中恢复。提高 Elasticsearch 的查询效率,Elasticsearch 会自动对搜索请求进行负载均衡。 |
gateway
gateway 代表 Elasticsearch 索引快照的存储方式,Elasticsearch 默认优先将索引存放到内存中,当内存满时再将这些索引持久化存储至本地硬盘。
gateway 对索引快照进行存储,当这个 Elasticsearch 集群关闭再重新启动时就会从 gateway 中读取索引备份数据。
Elasticsearch 支持多种类型的 gateway,有本地文件系统(默认)、分布式文件系统、Hadoop 的 HDFS 和阿里云的 OSS 云存储服务。
discovery.zen
- discovery.zen 代表 Elasticsearch 的自动发现节点机制,Elasticsearch 是一个基于 P2P 的系统,它先通过广播寻找存在的节点,再通过多播协议进行节点之间的通信,同时也支持点对点的交互。
Transport
- Transport 代表 Elasticsearch 内部节点或集群与客户端的交互方式,默认使用 TCP 协议进行交互。同时支持通过插件的方式集成,因此也可以使用 HTTP 协议(JSON 格式)、thrift、memcached、zeroMQ 等传输协议进行交互。
备份还原 elasticsearch 的 snapshot 到 minio
Redis
是一个持久化在磁盘上的内存数据库。数据模型是键值,但也支持许多不同类型的值。Strings, Lists, Sets, Sorted Sets, Hashes, Streams, HyperLogLogs, Bitmaps.
三个特点:
Redis 支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
Redis 不仅仅支持简单的 key-value 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。
Redis 支持数据的备份,即 master-slave 模式的数据备份。
Redis 优势
性能极高 – Redis 能读的速度是 110000 次/s,写的速度是 81000 次/s 。
丰富的数据类型 – Redis 支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
原子 – Redis 的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过 MULTI 和 EXEC 指令包起来。
丰富的特性 – Redis 还支持 publish/subscribe, 通知, key 过期等等特性。
内存存储 In Memory Storage
IO 多路复用和单线程实现 IO multiplexing and single-threaded implementation
优化的低级数据结构 Optimized lower-lever data structures
提升 Redis 的性能有两个方向:
优化网络 I/O 模块
- 零拷贝技术或者 DPDK 技术
- 利用多核优势
提高机器内存读写的速度
缓存
- Redis 是实施高可用性内存中缓存的极佳选择,它可以降低数据访问延迟、提高吞吐量,并可以减轻关系数据库和应用程序或 NoSQL 数据库和应用程序的负载。
聊天、消息收发和队列
- Redis 支持发布/订阅、模式匹配和各种数据结构
游戏排行榜
会话存储
富媒体流
地理空间
机器学习
实时分析
MinIO
云原生分布式文件存储 High Performance, Kubernetes Native Object Storage
高性能
- MinIO 是全球领先的对象存储先锋,目前在全世界有数百万的用户. 在标准硬件上,读/写速度上高达 183 GB / 秒 和 171 GB / 秒。
可扩展性
- MinIO 利用了 Web 缩放器的来之不易的知识,为对象存储带来了简单的缩放模型。
云的原生支持
- MinIO 是在过去 4 年的时间内从 0 开始打造的一款软件 ,符合一切原生云计算的架构和构建过程,并且包含最新的云计算的全新的技术和概念。 其中包括支持 Kubernetes 、微服和多租户的的容器技术。使对象存储对于 Kubernetes 更加友好。
开放全部源代码 + 企业级支持
- MinIO 基于 Apache V2 license 100% 开放源代码 。
与 Amazon S3 兼容
- 亚马逊云的 S3 API(接口协议) 是在全球范围内达到共识的对象存储的协议,是全世界内大家都认可的标准。 MinIO 在很早的时候就采用了 S3 兼容协议,并且 MinIO 是第一个支持 S3 Select 的产品。
简单
- 极简主义是 MinIO 的指导性设计原则。简单性减少了出错的机会,提高了正常运行时间,提供了可靠性,同时简单性又是性能的基础。
在实际业务中,存放各种各样的资源,例如产品图片用户头像等业务上的数据,tidb 备份的数据,elastic 快照,自动构建的文件(编译的 jar 包、配置环境、lib、镜像等),项目文档等。
使用 rclone 备份还原 minio 数据
kafka
Apache Kafka 是一个开源的分布式事件流平台,被成千上万的公司用于高性能数据管道、流分析、数据集成和关键任务应用。
Apache Kafka 是一种分布式数据存储,经过优化以实时提取和处理流数据。流数据是指由数千个数据源持续生成的数据,通常可同时发送数据记录。流平台需要处理这些持续流入的数据,按照顺序逐步处理。
Kafka 为其用户提供三项主要功能:
发布和订阅记录流
按照记录的生成顺序高效地存储记录流
实时处理记录流
Kafka 主要用于构建适应数据流的实时流数据管道和应用程序。它结合了消息收发、存储和流处理功能,能够存储历史和实时数据。
为什么使用 Kafka?
- Kafka 用于构建实时流数据管道和实时流应用程序。数据管道在不同系统之间可靠处理和移动数据,而流应用程序是消耗数据流的应用程序。例如,如果您要创建获取用户活动数据的数据管道以实时追踪人们如何使用您的网站,Kafka 将可在使支持数据管道的应用程序完成读取操作的同时,用于提取和存储流数据。Kafka 还经常用作消息代理解决方案,充当平台来处理和调解两个应用程序之间的通信。
Kafka 的工作原理
- Kafka 结合了两种消息收发模型、列队和发布-订阅,以向客户提供其各自的主要优势。通过列队可以跨多个使用器实例分发数据处理,因此具有很高的可扩展性。但是,传统队列不支持多订阅者。发布-订阅方法支持多订阅者,但是由于每条消息传送给每个订阅者,因此无法用于跨多个工作进程发布工作。Kafka 使用分区日志模型将这两种解决方案融合在一起。日志是一种有序的记录,这些日志分成区段或分区,分别对应不同的订阅者。这意味着,同一个主题可有多个订阅者,分别有各自的分区以获得更高的可扩展性。最后,Kafka 的模型带来可重放性,允许多个相互独立的应用程序从数据流执行读取以便按自己的速率独立地工作。
Kafka 方法的优势
可扩展
- Kafka 的分区日志模型允许跨多个服务器分发数据,使其可扩展性超越了在单服务器上应用的情况。
快速
- Kafka 可解耦数据流,因此延迟非常低,速度极快。
持久
- 分区可以跨多个服务器分发和和复制,数据全都写入到磁盘。这有助于防止服务器发生故障,使数据获得出色的容错能力和耐久性。
深入探究 Kafka 的架构
Kafka 通过将记录发布到不同的主题来调解两种不同的模型。每个主题都有一个分区日志,这是一种结构化提交日志,能够按顺序跟踪所有记录,并实时附加新记录。这些分区跨多个服务器分发和复制,从而获得高可扩展性、容错能力和并行机制。每个使用器都可在主题中获得一个分区,从而支持多订阅者,同时保持数据的顺序。通过结合这些消息收发模型,Kafka 兼具两者的优势。Kafka 还可通过将所有数据写入和复制到磁盘,充当可扩展性和容错能力非常高的存储系统。默认情况下,Kafka 一直保留磁盘上存储的数据,直到其空间用尽,但是用户可以设置保留限制。
Kafka 有四种 API:
- 创建器 API:用于将记录流发布到 Kafka 主题。
- 使用器 API:用于订阅主题并处理其记录流。
- 流 API:使应用程序能够像流处理器那样,用于从主题获取输入流,并将其转换为进入不同输出主题的输出流。
- 连接器 API:允许用户无缝地向其当前 Kafka 主题自动添加其他应用程序或数据系统。
Apache Kafka 与 RabbitMQ
- RabbitMQ 是一种开源消息代理,使用消息收发队列方法。队列在节点集群中传播,还可以复制,每条消息都只能传送到单个使用器。
| 特性 | Apache Kafka | RabbitMQ |
|---|---|---|
| 架构 | Kafka 使用分区日志模型,结合了消息收发队列和发送-订阅方法。 | RabbitMQ 使用消息收发队列。 |
| 可扩展性 | Kafka 允许跨不同服务器分发分区,因此具有可扩展性。 | 增加队列中的使用器数量可以将处理扩展到竞争使用器。 |
| 消息保留 | 基于策略,例如消息可以存储一天。用户可以配置此保留窗口。 | 基于确认,表示消息在使用后被删除。 |
| 多使用器 | 多个使用器可以订阅相同主题,因为 Kafka 允许将同一条消息重放指定的时间长度。 | 多个使用器无法全部接收同一条消息,因为消息在使用后将被删除。 |
| 复制 | 自动复制主题,但是用户可以手动将主题配置为不复制。 | 消息不会自动复制,但是用户可以手动将其配置为复制。 |
| 消息排序 | 由于采用了分区日志架构,每个使用器按顺序收到信息。 | 消息按照其到达队列的顺序传送给使用器。如果有竞争使用器,每个使用器都将处理该消息的子集。 |
| 协议 | Kafka 通过 TCP 使用二进制协议。 | 高级消息收发队列协议 (AMQP) 及通过插件获得的支持:MQTT、STOMP。 |
Kafka 比较重要的几个概念:
Producer(生产者) : 产生消息的一方。
Consumer(消费者) : 消费消息的一方。
Broker(代理) : 可以看作是一个独立的 Kafka 实例。多个 Kafka Broker 组成一个 Kafka Cluster。
同时,你一定也注意到每个 Broker 中又包含了 Topic 以及 Partition 这两个重要的概念:
Topic(主题) : Producer 将消息发送到特定的主题,Consumer 通过订阅特定的 Topic(主题) 来消费消息。
Partition(分区) : Partition 属于 Topic 的一部分。一个 Topic 可以有多个 Partition ,并且同一 Topic 下的 Partition 可以分布在不同的 Broker 上,这也就表明一个 Topic 可以横跨多个 Broker 。这正如我上面所画的图一样。
- Kafka 中的 Partition(分区) 实际上可以对应成为消息队列中的队列
ZooKeeper
- 一款开源的分布式应用程序协调服务。在消息队列 Kafka 版中,ZooKeeper 主要用于集群管理、配置管理、Leader 选举。ZooKeeper 是消息队列 Kafka 版的一部分,您无需感知 ZooKeeper。( 原始的 kafka2.8 版本后,用户可在完全不需要 ZooKeeper 的情况下运行 Kafka,该版本将依赖于 ZooKeeper 的控制器改造成了基于 Kafka Raft 的 Quorm 控制器。)
Broker
一个消息队列 Kafka 版服务端节点。消息队列 Kafka 版提供全托管服务,会根据您的实例的流量规格自动变化 Broker 的数量和配置。您无需关心具体的 Broker 信息。
Broker 是 Kafka 集群的骨干,负责从生产者(producer)到消费者(consumer)的接收、存储和发送消息。
集群
- 由多个 Broker 组成的集合。
实例
一个独立的消息队列 Kafka 版资源实体,对应一个集群。
发布/订阅模型
一种异步的服务间通讯模型。发布者无需了解订阅者的存在,直接将消息发送到特定的主题。订阅者无需了解发布者的存在,直接从特定的主题接收消息。消息队列 Kafka 版支持发布/订阅模型。更多信息,请参见消息队列 Kafka 版的发布/订阅模型。
订阅关系
- Topic 被 Group 订阅的情况。消息队列 Kafka 版支持查看订阅了指定 Topic 的在线 Group 的情况,非在线 Group 的情况无法查看。
Producer
- 向消息队列 Kafka 版发送消息的应用。
Consumer
- 从消息队列 Kafka 版接收消息的应用。
Group
- 一组具有相同 Group ID 的 Consumer。当一个 Topic 被同一个 Group 的多个 Consumer 消费时,每一条消息都只会被投递到一个 Consumer,实现消费的负载均衡。通过 Group,您可以确保一个 Topic 的消息被并行消费。
Topic
- 消息的主题,用于分类消息。
Topic 引流
- 消息队列 Kafka 版集群横向扩容完成后,使 Topic 流量重新均匀分布到扩容后的集群上的行为。更多信息,请参见 Topic 引流。
分区
- 消息的分区,用于存储消息。一个 Topic 由一个或多个分区组成,每个分区中的消息存储于一个或多个 Broker 上。
位点
- 消息到达分区时被指定的序列号。
最小位点
- 分区的最小位点,即当前分区的首条消息的位点。如何查看当前分区的最小位点,请参见查看分区状态。
最大位点
- 分区的最大位点,即当前分区的最新消息的位点。如何查看当前分区的最大位点,请参见查看分区状态。
消费位点
- 分区被当前 Consumer 消费了的消息的最大位点。如何查看消费位点,请参见查看消费状态。
最近消费时间
- Group 最近消费的消息被发布到消息队列 Kafka 版服务端的存储时间。如果消费没有堆积,那么这个时间接近发送时间。
堆积量
- 当前分区下的消息堆积总量,即最大位点减去消费位点的值。堆积量是一个关键指标,如果发现堆积量较大,则 Consumer 可能产生了阻塞,或者消费速度跟不上生产速度。此时需要分析 Consumer 的运行状况,尽力提升消费速度。您可以清除所有堆积消息,从最大位点开始消费,或按时间点进行位点重置。具体操作,请参见重置消费位点。
ACL
- 消息队列 Kafka 版提供的管理 SASL 用户和客户端使用 SDK 收发消息权限的服务,和开源 Apache Kafka 保持一致。ACL 只针对客户端使用 SDK 收发消息,与消息队列 Kafka 版控制台和 API 操作无关。
在实际业务中只是用作消息中间件,主要将设备返回的 mqtt 消息转发到 kafka,再订阅后进行业务处理。Kafka Web UI 使用的是简单的 Kafdrop。主要关心 topics 和 consumer groups。
gitlab
极狐 GitLab 一体化 DevOps 平台,从设计到投产,一个平台覆盖 DevSecOps 全流程。极狐 GitLab 帮助团队更快、更安全地交付更好的软件,提升研运效能,激发 DevOps 可观价值。
主要用作代码管理平台,项目通过设置 Webhooks,触发持续集成 (CI) 作业,参与自动构建流水线。
使用 Webhook 可以使得使用者在推送代码或创建 Issue 的时候可以触发一个事前配置好的 URL,而推送代码还是创建 Issue,抑或是合并请求,使用者可以自行在 GitLab 中进行定制,GitLab 会向设定的 Webhook 的 URL 发送一个 POST 请求。
Nexus Repository Manager
项目依赖代理仓库(maven、npm)
harbor
一个开源的可信的云原生注册表项目,可以存储、签署和扫描内容。
用作 docker 代理仓库、helm chart 仓库
Jenkins
项目持续集成
目前使用的是 kubeSphere 自带的 jenkins。
一般流程:Gitlab Webhook->jenkins->kubernetes pod(pipeline)
在项目源代码中创建了Jenkinsfile并提交它到源代码控制中提供了一些即时的好处:
自动地为所有分支创建流水线构建过程并拉取请求。(所以在时序图中没有看到显式的 git clone 的操作。)
在流水线上代码复查/迭代 (以及剩余的源代码)。
对流水线进行审计跟踪。
该流水线的真正的源代码, 可以被项目的多个成员查看和编辑。
KubeSphere 自带编译镜像需要宿主机存在 docker 环境,当前 kubernetes 集群使用 Containerd 作为容器运行时,需添加额外镜像以编译前后端项目。
前端编译流程
地端服务器 nginx 部署前端项目时,將项目文件目录挂载到 nfs 卷,將该 nfs 卷挂载到 jenkins pipeline pod 中,完成编译后直接写入 nfs 卷完成项目更新
云端服务器 nginx 部署前端项目时,將项目文件挂载到 minio,流水线在编译完成后通过 mc(minio client)將文件写入指定目录
后端编译流程
项目打包方案:
- 將项目打包为镜像:镜像过于臃肿,镜像上传云端耗时过长;项目更新多次后宿主机会留存大量旧版镜像,目前使用 containerd 容器运行时,没有完善的镜像回收机制
- 將项目打包 jar,上传 minio,k8s pod 初始化阶段从 minio 下载 jar
后端流水线较长,每个项目添加完整流水线要修改时难以维护,將流水线拆分两个部分:
- 项目流水线:拉取代码,调用 Maven 公共流水线並传入运行参数
- 项目流水线把项目的一些变量存到了 env.json,并在调用 common-pipeline 时有传 name 参数,里面有 SORCE_DIR(针对流水线配置的说明)
- 公共流水线:编译代码,上传 minio,更新项目 pod
- 从 env.json 中解析到项目流水线的参数,根据其内容进行构建。(针对流水线配置的说明,下同)
- 构建日志解析为 json-> 在 pipeline 配置中手动给项目 pom.xml 文件加入依赖 logstash-logback-encoder 和 logback.xml 文件
- 后台项目部署到云端时,先打包成 jar,在解压 jar,把 lib 和其他文件上传到本地或云端 MinIo,最后部署时使用 helm 模块的 nacos 配置(部分根据分支替换参数)进行编译
- 之所以不上传 jar 而是解压后上传部分内容,是因为前者几十兆,后者几百 K,节约云端带宽和加快部署速度。
KubeSphere
KubeSphere 是在 Kubernetes 之上构建的以应用为中心的多租户容器平台,提供全栈的 IT 自动化运维的能力,简化企业的 DevOps 工作流。KubeSphere 提供了运维友好的向导式操作界面,帮助企业快速构建一个强大和功能丰富的容器云平台。
KubeSphere 愿景是打造一个以 Kubernetes 为内核的云原生分布式操作系统,它的架构可以非常方便地使第三方应用与云原生生态组件进行即插即用(plug-and-play)的集成,支持云原生应用在多云与多集群的统一分发和运维管理。
特点:
完全开源
- 通过 CNCF 一致性认证的 Kubernetes 平台,100% 开源,由社区驱动与开发
简易安装
- 支持部署在任何基础设施环境,提供在线与离线安装,支持一键升级与扩容集群
功能丰富
- 在一个平台统一纳管 DevOps、云原生可观测性、服务网格、应用生命周期、多租户、多集群、存储与网络
模块化 & 可插拔
- 平台中的所有功能都是可插拔与松耦合,您可以根据业务场景可选安装所需功能组件
kubernetes
是用于自动部署、扩缩和管理容器化应用程序的开源系统。
容器编排管理


控制平面组件 Control Plane Components
- 控制平面组件会为集群做出全局决策,比如资源的调度。 以及检测和响应集群事件,例如当不满足部署的 replicas 字段时, 要启动新的 pod。
- kube-apiserver
- API 服务器是 Kubernetes 控制平面的组件, 该组件负责公开了 Kubernetes API,负责处理接受请求的工作。 API 服务器是 Kubernetes 控制平面的前端。
- etcd
- etcd 是兼顾一致性与高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。
- kube-scheduler
- kube-scheduler 是控制平面的组件, 负责监视新创建的、未指定运行节点(node)的 Pods, 并选择节点来让 Pod 在上面运行。
- kube-controller-manager
- 负责运行控制器进程。从逻辑上讲, 每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在同一个进程中运行。控制器包括:
- 节点控制器(Node Controller):负责在节点出现故障时进行通知和响应
- 任务控制器(Job Controller):监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
- 端点控制器(Endpoints Controller):填充端点(Endpoints)对象(即加入 Service 与 Pod)
- 服务帐户和令牌控制器(Service Account & Token Controllers):为新的命名空间创建默认帐户和 API 访问令牌
- cloud-controller-manager
- 允许你将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。
- 也是将若干逻辑上独立的控制回路组合到同一个可执行文件中, 供你以同一进程的方式运行。 你可以对其执行水平扩容(运行不止一个副本)以提升性能或者增强容错能力。控制器包括:
- 节点控制器(Node Controller):用于在节点终止响应后检查云提供商以确定节点是否已被删除
- 路由控制器(Route Controller):用于在底层云基础架构中设置路由
- 服务控制器(Service Controller):用于创建、更新和删除云提供商负载均衡器
Node 组件
- 节点组件会在每个节点上运行,负责维护运行的 Pod 并提供 Kubernetes 运行环境。
- kubelet
- kubelet 会在集群中每个节点(node)上运行。 它保证容器(containers)都运行在 Pod 中。
- kubelet 接收一组通过各类机制提供给它的 PodSpecs, 确保这些 PodSpecs 中描述的容器处于运行状态且健康。 kubelet 不会管理不是由 Kubernetes 创建的容器。
- kube-proxy
- kube-proxy 是集群中每个节点(node)所上运行的网络代理, 实现 Kubernetes 服务(Service) 概念的一部分。
- 容器运行时(Container Runtime)
- 容器运行环境是负责运行容器的软件。
插件(Addons)
- 插件使用 Kubernetes 资源(DaemonSet、 Deployment 等)实现集群功能。 因为这些插件提供集群级别的功能,插件中命名空间域的资源属于 kube-system 命名空间。
- DNS
- Kubernetes 启动的容器自动将此 DNS 服务器包含在其 DNS 搜索列表中。
- Web 界面(仪表盘)
- Dashboard 是 Kubernetes 集群的通用的、基于 Web 的用户界面。 它使用户可以管理集群中运行的应用程序以及集群本身, 并进行故障排除。
- 容器资源监控
- 容器资源监控 将关于容器的一些常见的时间序列度量值保存到一个集中的数据库中, 并提供浏览这些数据的界面。
- 集群层面日志
- 集群层面日志机制负责将容器的日志数据保存到一个集中的日志存储中, 这种集中日志存储提供搜索和浏览接口。
工作负载
工作负载是在 Kubernetes 上运行的应用程序。
在 Kubernetes 中,无论你的负载是由单个组件还是由多个一同工作的组件构成, 你都可以在一组 Pod 中运行它。 在 Kubernetes 中,Pod 代表的是集群上处于运行状态的一组 容器 的集合。
Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
Pod 是一组(一个或多个)容器; 这些容器共享存储、网络、以及怎样运行这些容器的声明。
为了减轻用户的使用负担,通常不需要用户直接管理每个 Pod。 而是使用负载资源来替用户管理一组 Pod。 这些负载资源通过配置 控制器 来确保正确类型的、处于运行状态的 Pod 个数是正确的,与用户所指定的状态相一致。
Kubernetes 提供若干种内置的工作负载资源:
Deployment 和 ReplicaSet (替换原来的资源 ReplicationController)。 Deployment 很适合用来管理你的集群上的无状态应用,Deployment 中的所有 Pod 都是相互等价的,并且在需要的时候被替换。
StatefulSet 让你能够运行一个或者多个以某种方式跟踪应用状态的 Pods。 例如,如果你的负载会将数据作持久存储,你可以运行一个 StatefulSet,将每个 Pod 与某个 PersistentVolume 对应起来。你在 StatefulSet 中各个 Pod 内运行的代码可以将数据复制到同一 StatefulSet 中的其它 Pod 中以提高整体的服务可靠性。
DaemonSet 定义提供节点本地支撑设施的 Pods。这些 Pods 可能对于你的集群的运维是 非常重要的,例如作为网络链接的辅助工具或者作为网络 插件 的一部分等等。每次你向集群中添加一个新节点时,如果该节点与某 DaemonSet 的规约匹配,则控制面会为该 DaemonSet 调度一个 Pod 到该新节点上运行。
Job 和 CronJob。 定义一些一直运行到结束并停止的任务。Job 用来表达的是一次性的任务,而 CronJob 会根据其时间规划反复运行。
服务、负载均衡和联网
Kubernetes 网络模型
集群中每一个 Pod 都会获得自己的、 独一无二的 IP 地址, 这就意味着你不需要显式地在 Pod 之间创建链接,你几乎不需要处理容器端口到主机端口之间的映射。 这将形成一个干净的、向后兼容的模型;在这个模型里,从端口分配、命名、服务发现、 负载均衡、 应用配置和迁移的角度来看,Pod 可以被视作虚拟机或者物理主机。
Kubernetes 强制要求所有网络设施都满足以下基本要求(从而排除了有意隔离网络的策略):
Pod 能够与所有其他节点上的 Pod 通信, 且不需要网络地址转译(NAT)
节点上的代理(比如:系统守护进程、kubelet)可以和节点上的所有 Pod 通信
Kubernetes 网络解决四方面的问题:
一个 Pod 中的容器之间通过本地回路(loopback)通信。
集群网络在不同 pod 之间提供通信。
Service 资源允许你 向外暴露 Pods 中运行的应用, 以支持来自于集群外部的访问。
可以使用 Services 来发布仅供集群内部使用的服务。
存储
卷(Volume)
Container 中的文件在磁盘上是临时存放的,这给 Container 中运行的较重要的应用程序带来一些问题。 问题之一是当容器崩溃时文件丢失。 kubelet 会重新启动容器,但容器会以干净的状态重启。 第二个问题会在同一 Pod 中运行多个容器并共享文件时出现。 Kubernetes 卷(Volume) 这一抽象概念能够解决这两个问题。
Kubernetes 支持很多类型的卷。 Pod 可以同时使用任意数目的卷类型。 临时卷类型的生命周期与 Pod 相同,但持久卷可以比 Pod 的存活期长。 当 Pod 不再存在时,Kubernetes 也会销毁临时卷;不过 Kubernetes 不会销毁持久卷。 对于给定 Pod 中任何类型的卷,在容器重启期间数据都不会丢失。
卷的核心是一个目录,其中可能存有数据,Pod 中的容器可以访问该目录中的数据。 所采用的特定的卷类型将决定该目录如何形成的、使用何种介质保存数据以及目录中存放的内容。
卷挂载在镜像中的指定路径下。 Pod 配置中的每个容器必须独立指定各个卷的挂载位置。
卷不能挂载到其他卷之上(不过存在一种使用 subPath 的相关机制),也不能与其他卷有硬链接。
配置
一般配置提示
定义配置时,请指定最新的稳定 API 版本。
在推送到集群之前,配置文件应存储在版本控制中。 这允许你在必要时快速回滚配置更改。 它还有助于集群重新创建和恢复。
使用 YAML 而不是 JSON 编写配置文件。虽然这些格式几乎可以在所有场景中互换使用,但 YAML 往往更加用户友好。
只要有意义,就将相关对象分组到一个文件中。 一个文件通常比几个文件更容易管理。 请参阅 guestbook-all-in-one.yaml 文件作为此语法的示例。
另请注意,可以在目录上调用许多 kubectl 命令。 例如,你可以在配置文件的目录中调用 kubectl apply。
除非必要,否则不指定默认值:简单的最小配置会降低错误的可能性。
将对象描述放在注释中,以便更好地进行内省。
如果可能,不要使用独立的 Pods(即,未绑定到 ReplicaSet 或 Deployment 的 Pod)。 如果节点发生故障,将不会重新调度独立的 Pods。
服务
在创建相应的后端工作负载(Deployment 或 ReplicaSet),以及在需要访问它的任何工作负载之前创建 服务。 当 Kubernetes 启动容器时,它提供指向启动容器时正在运行的所有服务的环境变量。
一个可选(尽管强烈推荐)的集群插件 是 DNS 服务器。DNS 服务器为新的 Services 监视 Kubernetes API,并为每个创建一组 DNS 记录。 如果在整个集群中启用了 DNS,则所有 Pods 应该能够自动对 Services 进行名称解析。
除非绝对必要,否则不要为 Pod 指定 hostPort。 将 Pod 绑定到 hostPort 时,它会限制 Pod 可以调度的位置数,因为每个 <hostIP, hostPort, protocol>组合必须是唯一的。
使用标签:定义并使用标签来识别应用程序 或 Deployment 的 语义属性
使用 kubectl apply -f <directory>。 它在 <directory> 中的所有 .yaml、.yml 和 .json 文件中查找 Kubernetes 配置,并将其传递给 apply。
ConfigMap
ConfigMap 是一种 API 对象,用来将非机密性的数据保存到键值对中。使用时, Pods 可以将其用作环境变量、命令行参数或者存储卷中的配置文件。
ConfigMap 将你的环境配置信息和 容器镜像 解耦,便于应用配置的修改。
Secret
Secret 是一种包含少量敏感信息例如密码、令牌或密钥的对象。 这样的信息可能会被放在 Pod 规约中或者镜像中。 使用 Secret 意味着你不需要在应用程序代码中包含机密数据。
由于创建 Secret 可以独立于使用它们的 Pod, 因此在创建、查看和编辑 Pod 的工作流程中暴露 Secret(及其数据)的风险较小。 Kubernetes 和在集群中运行的应用程序也可以对 Secret 采取额外的预防措施, 例如避免将机密数据写入非易失性存储。
Secret 类似于 ConfigMap 但专门用于保存机密数据。
为 Pod 和容器管理资源
当你定义 Pod 时可以选择性地为每个 容器设定所需要的资源数量。 最常见的可设定资源是 CPU 和内存(RAM)大小;此外还有其他类型的资源。
当你为 Pod 中的 Container 指定了资源 请求 时, kube-scheduler 就利用该信息决定将 Pod 调度到哪个节点上。 当你还为 Container 指定了资源 限制 时,kubelet 就可以确保运行的容器不会使用超出所设限制的资源。 kubelet 还会为容器预留所 请求 数量的系统资源,供其使用
一个 CPU 等于 1 个物理 CPU 核 或者 1 个虚拟核,为 1000m,一千毫核
Containerd
业界标准的容器运行时间,强调简单性、稳健性和可移植性
使用原因:Kubernetes 在 v1.24 版移除了 dockershim。
Kubernetes 增加了对使用其他容器运行时的支持。创建 CRI 标准是为了实现编排器(如 Kubernetes)和许多不同的容器运行时之间交互操作。
Docker Engine 没有实现(CRI)接口,因此 Kubernetes 项目创建了特殊代码来帮助过渡, 并使 dockershim 代码成为 Kubernetes 的一部分。
因为是临时方案、维护者的沉重负担、较新的 CRI 运行时中实现了与 dockershim 不兼容的功能,所以 1.24 移除了 dockershim。
所以业务中没有使用 docker 作为容器运行时,而是使用 Containerd。
Kubelet 通过 Container Runtime Interface (CRI) 与容器运行时交互,以管理镜像和容器。Containerd 调用链更短,组件更少,更稳定,占用节点资源更少。 建议选择 containerd。
Containerd 不支持 docker 那些命令,但可以使用其他插件实现类似的命令使用。例如nerdctl 是一个与 docker cli 风格兼容的 containerd 客户端工具,而且直接兼容 docker compose 的语法。
Helm
Kubernetes 包管理器
Helm 是查找、分享和使用软件构建 Kubernetes 的最优方式。
Helm 帮助您管理 Kubernetes 应用—— Helm Chart,即使是最复杂的 Kubernetes 应用程序,都可以帮助您定义,安装和升级。Helm Chart 易于创建、发版、分享和发布。
使用 Helm,需要一个 Kubernetes 集群。对于 Helm 的最新版本,我们建议使用 Kubernetes 的最新稳定版, 在大多数情况下,它是倒数第二个次版本。
当一个 Helm 的新版本发布时,它是针对 Kubernetes 的一个特定的次版本编译的。例如:
Helm 版本 支持的 Kubernetes 版本
3.9.x 1.24.x - 1.21.x
3.8.x 1.23.x - 1.20.x
3.7.x 1.22.x - 1.19.x
3.6.x 1.21.x - 1.18.x
Helm 三大概念:
Chart 代表着 Helm 包。它包含在 Kubernetes 集群内部运行应用程序,工具或服务所需的所有资源定义。你可以把它看作是 Homebrew formula,Apt dpkg,或 Yum RPM 在 Kubernetes 中的等价物。
Repository(仓库) 是用来存放和共享 charts 的地方。它就像 Perl 的 CPAN 档案库网络 或是 Fedora 的 软件包仓库,只不过它是供 Kubernetes 包所使用的。
Release 是运行在 Kubernetes 集群中的 chart 的实例。一个 chart 通常可以在同一个集群中安装多次。每一次安装都会创建一个新的 release。以 MySQL chart 为例,如果你想在你的集群中运行两个数据库,你可以安装该 chart 两次。每一个数据库都会拥有它自己的 release 和 release name。
Helm 安装 charts 到 Kubernetes 集群中,每次安装都会创建一个新的 release。你可以在 Helm 的 chart repositories 中寻找新的 chart。
使用:
1 | 指定配置文件安裝项目(指定配置安装kafka到k8s) |