nodejs-snowflake分布式ID
雪花算法
https://www.npmjs.com/package/nodejs-snowflake
Number or String
首先需要确定全局唯一ID是整型还是字符串?如果是字符串,那么现有的UUID就完全满足需求,不需要额外的工作。缺点是字符串作为ID占用空间大,索引效率比整型低。
如果采用整型作为ID,那么首先排除掉32位int类型,因为范围太小,必须使用64位long型。
数据库自增ID缺点
数据库自增ID的缺点是数据在插入前,无法获得ID。数据在插入后,获取的ID虽然是唯一的,但一定要等到事务提交后,ID才算是有效的。有些双向引用的数据,不得不插入后再做一次更新
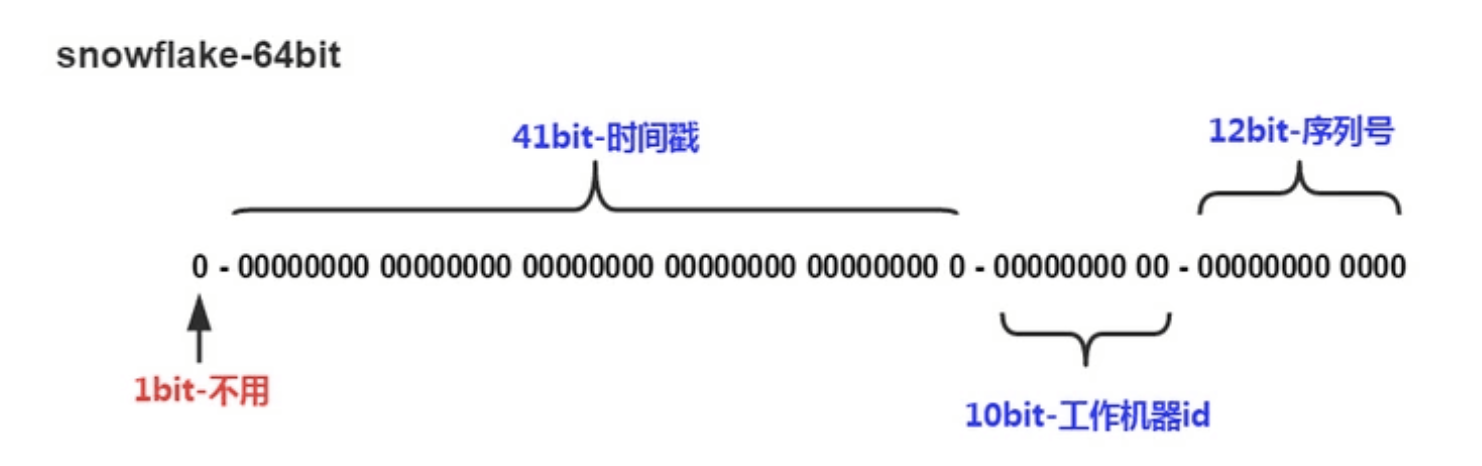
snowflake
分布式ID解决方案
SnowFlake可以保证:
- 同一台服务器所有生成的id按时间趋势递增
- 整个分布式系统内不会产生重复id(因为有datacenterId和workerId来做区分)