
hive和数据库对比总结
hive和数据库对比总结
基本概念
Hadoop:
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了POSIX(可移植操作系统接口)的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
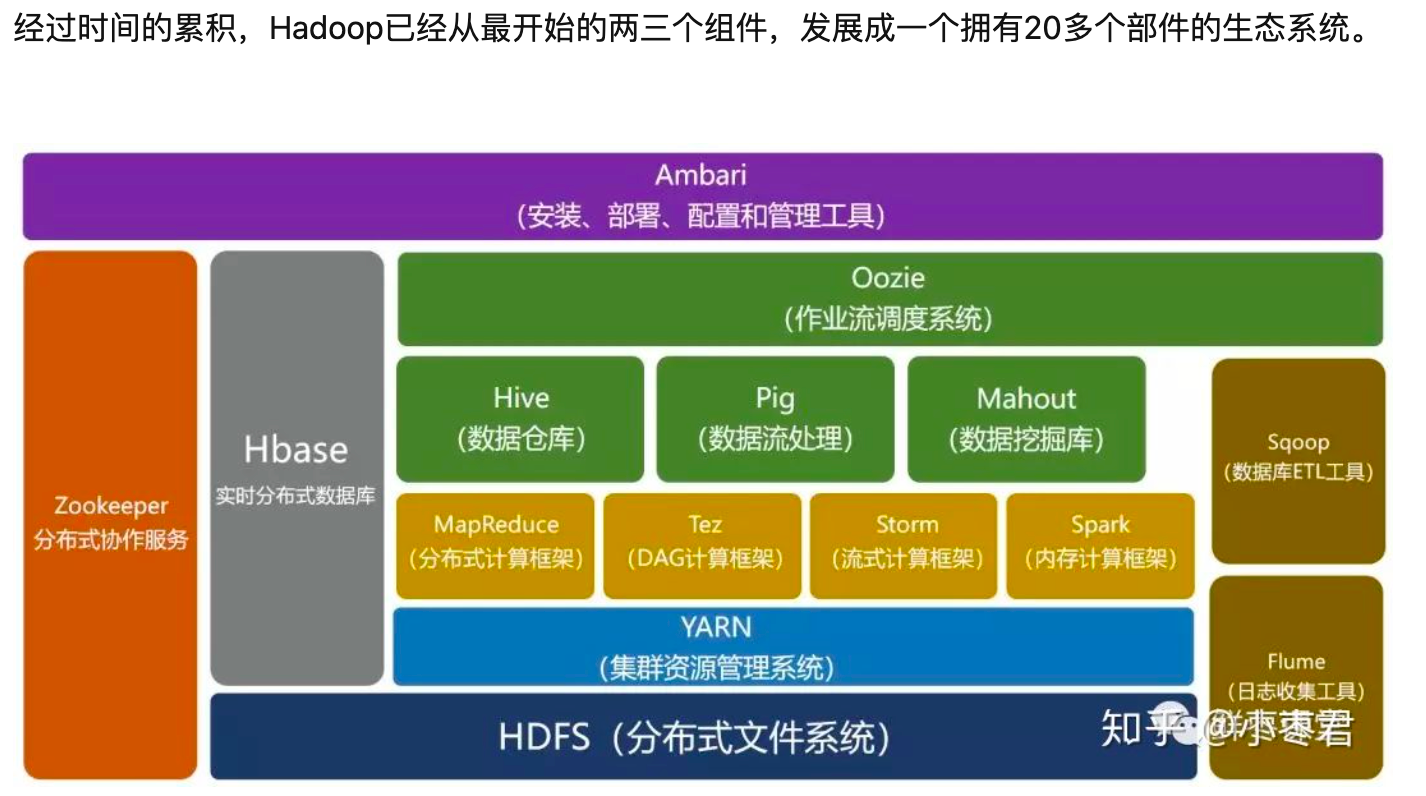
简单了解一下hadoop的前世今生:https://zhuanlan.zhihu.com/p/54994736?utm_source=wechat_session&utm_medium=social&utm_oi=1153751120357687296
MapReduce:
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念”Map(映射)”和”Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。
它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,map的主要输入是一对<key , value>值,经过map计算后输出一对<key , value>值;然后将相同key合并,形成<key , value集合>;再将这个<key , value集合>输入并发的Reduce(归约)函数,经过计算输出零个或多个<key , value>对。
Spark:
Spark是一种比MapReduce更高效读HDFS文件数据的方式(还支持其他数据源,如kafka等),并且读取到数据后(做一些业务逻辑的数据处理等),可以支持写入各种数据源中,例如Redis、MySQL等。
Hadoop MapReduce 是一种用于处理大数据集的编程模型,它采用并行的分布式算法。开发人员可以编写高度并行化的运算符,而不用担心工作分配和容错能力。不过,MapReduce 所面对的一项挑战是它要通过连续多步骤流程来运行某项作业。在每个步骤中,MapReduce 要读取来自集群的数据,执行操作,并将结果写到 HDFS。因为每个步骤都需要磁盘读取和写入,磁盘 I/O 的延迟会导致 MapReduce 作业变慢。开发 Spark 的初衷就是为了突破 MapReduce 的这些限制,它可以执行内存中处理,减少作业中的步骤数量,并且跨多项并行操作对数据进行重用。借助于 Spark,将数据读取到内存、执行操作和写回结果仅需要一个步骤,大大地加快了执行的速度。
hive:
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件(例如HDFS文件)映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。
Hive的优点是学习成本低,可以通过类似SQL语句(例如Presto SQL)实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。
Presto 或 PrestoDB:
Presto(或 PrestoDB)是一种开源的分布式 SQL 查询引擎,从头开始设计用于针对任何规模的数据进行快速分析查询。
它既可支持非关系数据源,例如 Hadoop 分布式文件系统 (HDFS)、Amazon S3、Cassandra、MongoDB 和 HBase,又可支持关系数据源,例如 MySQL、PostgreSQL、Amazon Redshift、Microsoft SQL Server 和 Teradata。
hive和数据库的比较:
从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。数据库可以用在 Online 的应用中,但是Hive 是为数据仓库而设计的(用于数据归档等)。
1)查询语言
由于SQL被广泛的应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
2)数据存储位置
Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
3)数据格式
Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、”\t”、”\x001″)、行分隔符(”\n”)以及读取文件数据的方法(Hive 中默认有三个文件格式TextFile,SequenceFile以及RCFile)。由于在加载数据的过程中,不需要从用户数据格式到 Hive 定义的数据格式的转换,因此,Hive在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的HDFS目录中。而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
4)数据更新
由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive中不支持对数据的改写和添加,所有的数据都是在加载的时候中确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET修改数据。
5)索引
之前已经说过,Hive在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些Key建立索引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
6)执行
Hive中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的(类似 select * from tbl的查询不需要MapReduce)。而数据库通常有自己的执行引擎。
7)执行延迟
之前提到,Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce框架。由于MapReduce 本身具有较高的延迟,因此在利用MapReduce 执行Hive查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时 候,Hive的并行计算显然能体现出优势。
8)可扩展性
由于Hive是建立在Hadoop之上的,因此Hive的可扩展性是和Hadoop的可扩展性是一致的(世界上最大的Hadoop 集群在 Yahoo!,2009年的规模在4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有100台左右。
9)数据规模
由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。