
Nodejs监控方案
Nodejs监控方案
BFF 上线后,未提供监控能力,无法主动发现报错、接口性能等,需要有相应的指标监控 BFF 程序运行状况。
本方案以监控 BFF (Nest.js 应用),描述从指标制定到查看数据面板的过程。
目标
BFF 的监控主要包含系统监控、服务监控、业务监控、报警响应四大类
监控指标
| 类型 | 指标类 | 指标名 | 描述 |
|---|---|---|---|
| 系统监控 | 容器指标 | 容器 CPU | Pod CPU 使用率 |
| 进程指标 | 进程 CPU | 进程 CPU 使用率 | |
| 服务监控 | HTTP 指标 | 接口 QPS | 所有接口请求量 |
| 接口 P99 延时 | 接口响应时间,取前 99% | ||
| 接口 P95 延时 | 接口响应时间,取前 99% | ||
| 接口成功率 | http 状态码 200 | ||
| RPC指标 | 同HTTP指标 | / | |
| Spex指标 | 同HTTP指标 | / | |
| 业务监控 | 业务指标 | 根据业务具体场景而定 | / |
报警响应
- 支持报警规则配置
- 支持邮件通知业务 owner
架构设计
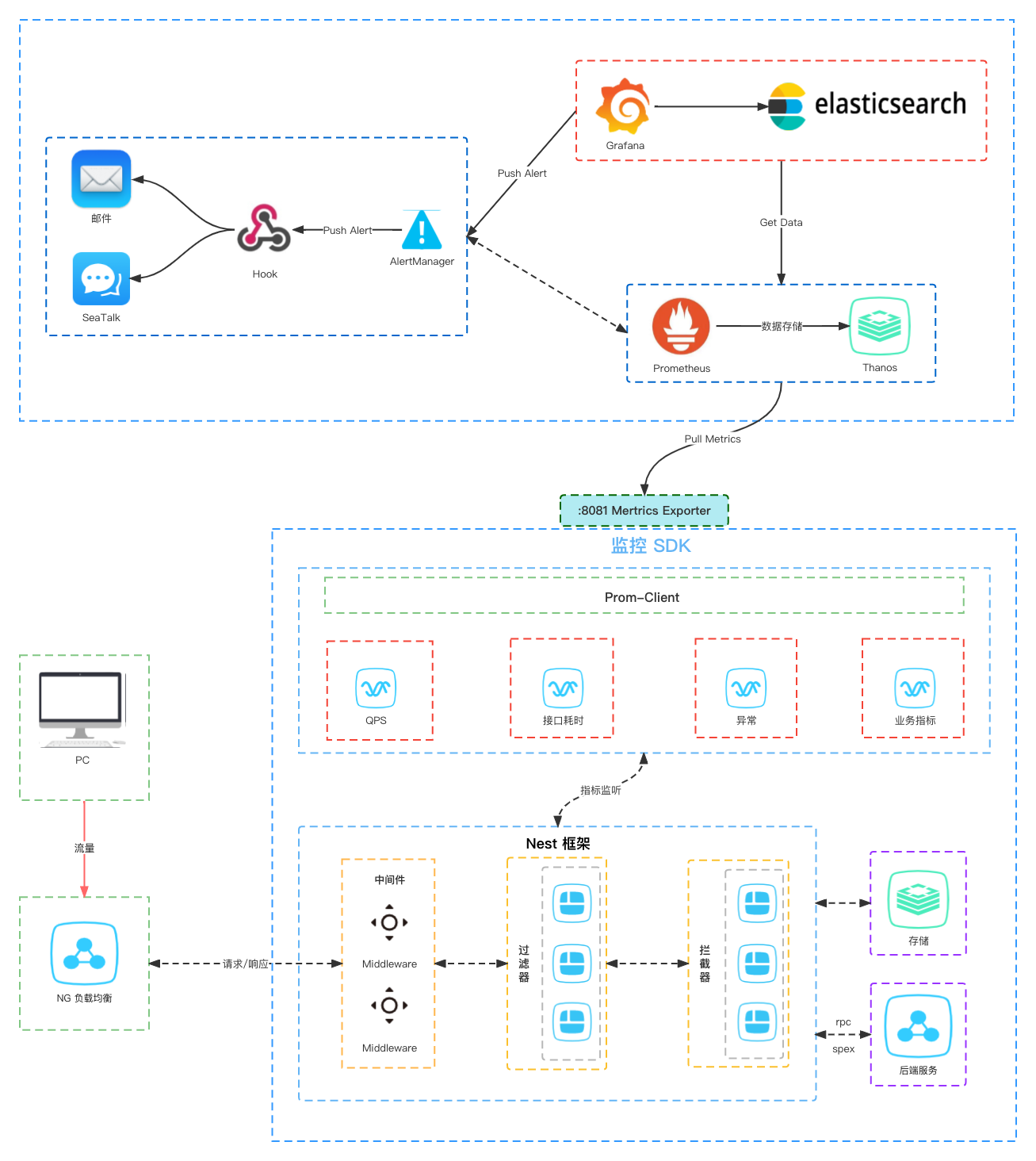
主要架构模块
按功能类别主要划分为三个类模块。
- 监控 SDK
- 以项目(Project)维度, 每个项目按初始化参数创建一个 SDK 类实例,用于配置追踪与上报的类别信息。
- 负责具体类别的数据处理与指标收集,并提供给 Prometheus
- 业务方直接引入使用,不需要关心指标采集逻辑
- 监控面板
- 以项目(Project)维度, 每个项目创建自己的监控大盘
- 负责将数据归类并展示对应的可视化图表
- 告警
- 监听上报数据,支持告警阈值规则配置
- 负责告警异常到指定 owner
技术选型
- 基于 nest 实现监控 SDK
- 普罗米修斯提供数据采集能力
- Grafana 提供可视化数据展示
- AlertManager 提供告警能力
核心流程设计
SDK 设计
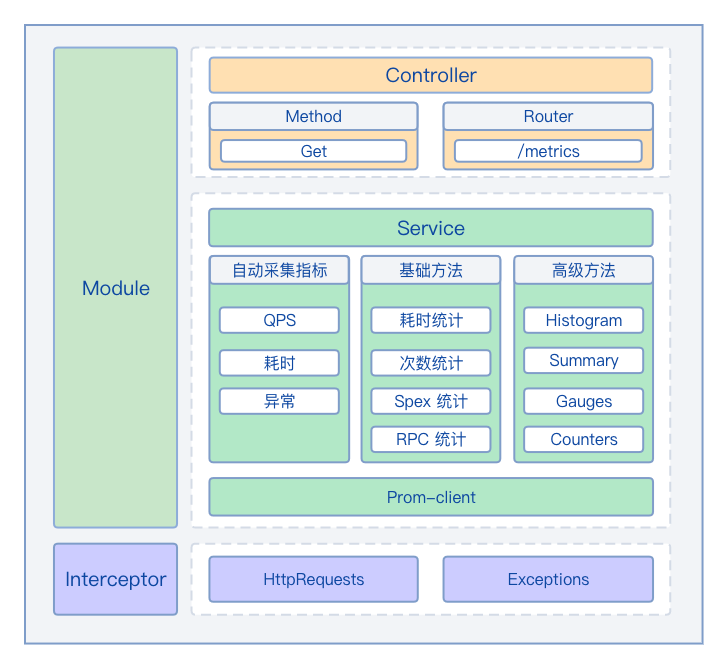
Controller 设计
- Method
- 提供 get 方法,供普罗米修斯访问
- Router
- 提供 /metrics 接口,暴露采集到的所有指标给普罗米修斯
Service 设计
Service 基于 prom-client 进行封装,是 SDK 的核心逻辑,提供了对指标的采集
- 默认指标
- 导出 Prom-client 采集的默认指标
- SDK 自动采集的指标
- QPS
- 接口耗时
- 接口错误数
- 暴露给业务方的方法
- 基础 API
- 耗时统计
- 次数统计(包含异常次数、成功次数)
- Spex 统计(预留)
- RPC 统计(预留)
- 高级 API
- Histogram(柱状图):统计数据的分布情况(比如 Http_response_time 的时间分布)
- Summary(摘要):主要用于表示一段时间内数据采样结果(请求持续的时间或响应大小)
- Gauges(瞬态):最简单的度量指标,监测瞬间状态(监控硬盘容量或者内存的使用量)
- Counters(累加态):从数据量0开始累积计算,在理想状态下只能是永远的增长不会降低
- 基础 API
拦截器设计
拦截器的作用主要是全局采集我们所需要的指标,同时不让业务方感知
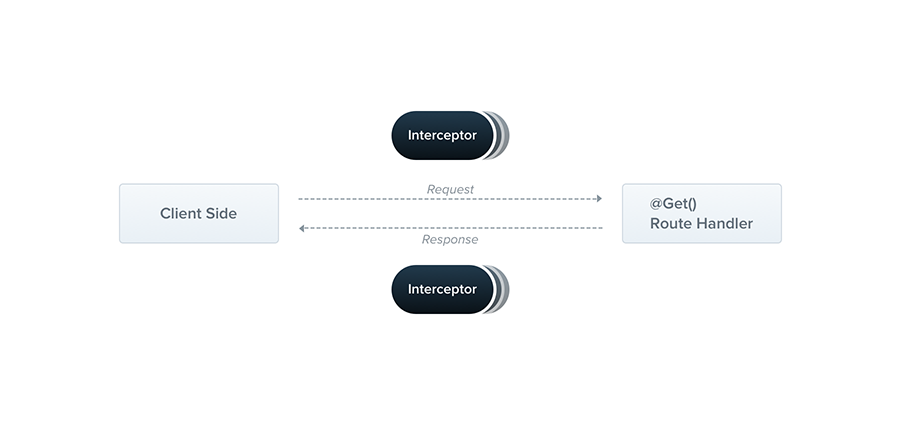
- HttpRequests 拦截器
- 所有请求都会通过 httpRequests 拦截器,在这里进行以下指标收集
- QPS
- 接口耗时
- Exception 拦截器
- 所有未捕获异常都会经过 Exception 拦截器,在这里进行一下指标收集
- 接口错误数
如何接入
应用框架应该如何接入
- 应用框架需要默认依赖该 SDK
现有项目应该如何接入
- 在现有服务中新增依赖该 SDK
- 将 SDK 中的 Module 注册到 main 中
- 并在启动模版中添加对 8081 端口的监控
- 在 main 中引入拦截器
*监控面板设计*
*面板上需要体现出哪些指标*
*通用指标展示*
- CPU
- 内存
- QPS
- 接口耗时
- 接口错误率
其余指标展示(可选)
- MySQL 数据库指标
- Shopee 线上的数据库已经装有对应 exporter ,无需手动导出指标数据
- Spex 指标
- RPC 指标
*如何展示指标*
目前普罗米修斯支持的类型有下面几类
- Histogram(柱状图):统计数据的分布情况(比如 Http_response_time 的时间分布)
- Summary(摘要):主要用于表示一段时间内数据采样结果(请求持续的时间或响应大小)
- Gauges(瞬态):最简单的度量指标,监测瞬间状态(监控硬盘容量或者内存的使用量)
- Counters(累加态):从数据量0开始累积计算,在理想状态下只能是永远的增长不会降低
指标展示分类如下
| 指标 | 类型 |
|---|---|
| CPU | Gauges(瞬态) & Summary(摘要) |
| 内存 | Gauges(瞬态) & Summary(摘要) |
| QPS | Gauges(瞬态) |
| 接口耗时 | Histogram(柱状图)P99、P90 |
| 接口错误率 | Histogram(柱状图)P99、P90 |
| 数据库成功率 | Histogram(柱状图) |
| Spex 指标 | Histogram(柱状图)P99、P90 |
| RPC 指标 | Histogram(柱状图)P99、P90 |
*告警设计*
*哪些指标需要告警*
告警可以让我们及时响应线上异常,避免问题被动发现
通常我们会对重要或者紧急的线上指标进行告警响应,以下指标需要我们进行告警
- CPU
- 内存
- 接口错误率
- 数据库 I/O 异常
- Spex 异常
- RPC 异常
*告警策略*
| 指标名 | 介绍 | 告警阈值 | 告警方式 |
|---|---|---|---|
| CPU | 进程 CPU 使用率 | >= 80%,持续5分钟 | sea talk & 邮件 |
| Memory | 进程 Mem 使用率 | >= 80%,持续5分钟 | sea talk & 邮件 |
| 接口错误率 | 任何一个接口的错误率 | 每分钟 > 0% | 邮件 |
| 每分钟 > 5% | sea talk | ||
| 数据库异常 | 数据库 I/O 异常 | 每分钟 > 0 | 邮件 |
| 每分钟 > 10 | sea talk | ||
| Spex 异常 | 任何一个 Spex 异常 | 每分钟 > 0 | 邮件 |
| 每分钟 > 10 | sea talk | ||
| RPC 异常 | 任何一个 RPC 异常 | 每分钟 > 0 | 邮件 |
| 每分钟 > 10 | sea talk |