MySQL开发规范
介绍:MySQL 开发规范
MySQL开发规范
MySQL 开发规范
背景
对目前Node项目内的MYSQL开发方式拟定一个大致的规范。
命名规范
- 统一按照
lower_case_with_underscores的命名方式 - 禁止使用mysql的关键字和保留字
- 命名的length长度小于32
DB
- 以
_db为后缀,如account_db,shopee_account_db - 以业务代码为前缀,如
shopee_account_db,gop_txn_db - 如果db是单独为某个region,如
shopee_admin_vn_db - 如果要分库,把sharding id放到_db后面,sharding id从0开始,占8位,如
shopee_seller_dms_sg_db和shopee_seller_dms_id_db_00001000 - db名称长度需要小于42(DBA)
Table
- 以
_tab为后缀,表名不适用复数名词,如果要分表,把sharding id放到_tab后面,sharding id从0开始,占8位 ,如order_tab_00000000和login_log_tab_00201801 - table名称长度需要小于48(DBA)
Field
- 布尔类型字段,is_做为前缀,如
is_active - 如果该字段是外键,并且引用的另一个表是整数主键,则应以
_id为后缀
Index
- 唯一索引使用
uniq_做为前缀,并按顺序紧跟字段名,如uniq_key1_key2 - 非唯一索引使用
idx_做为前缀,并按顺序紧跟字段名,如idx_key1_key2
建表规范
ENGINE=InnoDB- 通常字符编码选用
utf8mb4_unicode_ci,特殊情况可以考虑latin1_general_ci,其中_ci表明不区分大小写,而字符集可以参考这里 - 如果此字段需要区分大小写,需要在字段中使用
*_cs - 禁止在数据库中存储图片,文件等大的二进制数据。通常存储于文件服务器,数据库只存储文件地址信息
- 禁止使用外键,如果要保证完整性,应由应用层实现
- MySQL外键实现比较简单粗暴,性能不好
- 不建议在 MySQL 上放置任何计算逻辑。我们将 MySQL 作为后端存储,不允许外键或存储例程
- 必须为字段添加注释,注释要言简意赅,不建议很长很详尽的注释
- 必须包含三个字段
- 主键:
'id' bigint(20) unsigned NOT NULL AUTO_INCREMENT - 两个日期字段:
create_time,update_time,对表的记录进行更新的时候,必须更新update_time
- 主键:
- 新增列,禁止指定位置 (FIRST / AFTER),而是将新列仅作为最后一列附加
- 所有字段均定义为NOT NULL
- 禁止使用ENUM,用TINYINT代替
- ENUM增加新值要进行DDL操作,而DDL对于MYSQL来说维护成本很高
- 使用INT UNSIGNED (UNIX timestamp)存储时间
- 使用INT UNSIGNED存储IPV4地址
- 除非必要,否则不要设置默认值
- 在现有表上添加新字段时建议使用默认值,以确保平滑升级/回滚
- 数值类型尽量使用严格数值数据类型 (比如INT, DECIMAL),而不是近似数值数据类型 (比如FLOAT, DOUBLE)
- 在存储的时候,float 和 double 都存在精度损失的问题,很可能在比较值的时候,得到不正确的结果。如果存 储的数据范围超过 decimal 的范围,建议将数据拆成整数和小数并分开存储。
- 非负数值类型设置为UNSIGNED
- 定义 ID 值尽可能使用
BIGINT unsigned
索引规范
- 建议单表索引数量不超过5个
- 太多索引会影响写性能
- 生成执行计划时,如果索引太多,会降低性能,并可能导致MySQL选择不到最优索引
- 异常复杂的查询需求,可以选择ES等更为适合的方式存储
- 建议组合索引的字段不超过5个
- 如果5个字段还不能极大缩小row范围,八成是设计有问题
- 对于频繁的查询优先考虑使用覆盖索引
- 不建议在频繁更新的字段上建立索引
- 理解组合索引最左前缀原则,避免重复索引,如果建立了(a,b,c),相当于建立了(a), (a,b), (a,b,c)
- 非必要不要进行JOIN查询,如果要进行JOIN查询,被JOIN的字段必须类型相同,并建立索引
- JOIN字段类型不一致,会自动进行类型转换,可能导致全表扫描
查询规范
- 禁止使用SELECT *,需要哪些字段必须明确写明,使用SELECT <字段列表> 查询
- 增加查询分析器解析成本
- 无用字段增加网络消耗,尤其是 text 类型的字段
- LIKE查询时,禁止用 % 通配符最左前导
- 不要在WHERE使用函数
- 不要使用SQL运算
- 能用UNION ALL不要用UNION
- UNION会对结果做去重,会产生临时表
- 超1000行的批量写(UPDATE、DELETE、INSERT)操作,要分批多次进行操作,每批次LIMIT 1000,并在两个批次之间引入延时(比如1s)
- 不能用 use <> NULL, = NULL, in (NULL), not in (NULL), group by NULL, aggregation method(NULL), 只能用
is NULL和is not NULL,因为NULL 不是一个值,不能做任何比较 - 不允许在 MySQL 客户端执行 SQL 直接更新生产数据库中的数据(例如修复数据)
- 您可以 DB Update Data在 GTS中创建 带有票证类型的票证,并将 SQL 放入票证中。DBA 将帮助运行 SQL
- 您还可以编写脚本来更新数据,并将脚本传递给 DBA 进行审核,然后再在生产环境中运行脚本
- 为了安全起见,请不要 在 GTS 票证中提供
DROP TABLE或命令。DROP DATABASE通常我们可以使用RENAME TABLE更改表名来代替。要从实时数据库中物理删除表或数据库,通常我们重命名表,然后再等待 90 天。如果没有报告错误/异常,或者没有人想恢复它们,那么可以安全地删除它们。
MYSQL最佳实践
软删除
使用软删除,而不是硬删除,使用is_deleted的标志位来标识删除状态
硬删除可能会导致数据库性能下降,有时硬删除确实有必要需要提单给DBA处理
TEXT/BLOB
尽可能不去使用TEXT/BLOB,如确实需要,将比较大的列拆分到单独的表中
- DB大小越小,性能越好
- 不推荐在InnoDB表里面包含多个TEXT/BLOB列
- 不推荐使用:MEDIUMTEXT/LONGBLOB/…
integer timestamp
- 建议使用INT UNSIGNED 或者 BIGINT Unix timestamp
- 永远使用UTC timestamp
- UTC时间戳更容易在多个时区之间进行时间转换
- 不需要额外的字段存储时区信息
- int类型更高效
分库分表
- 单表>单库分表>分库分表,在满足业务场景的情况下,优先级逐渐降低
额外
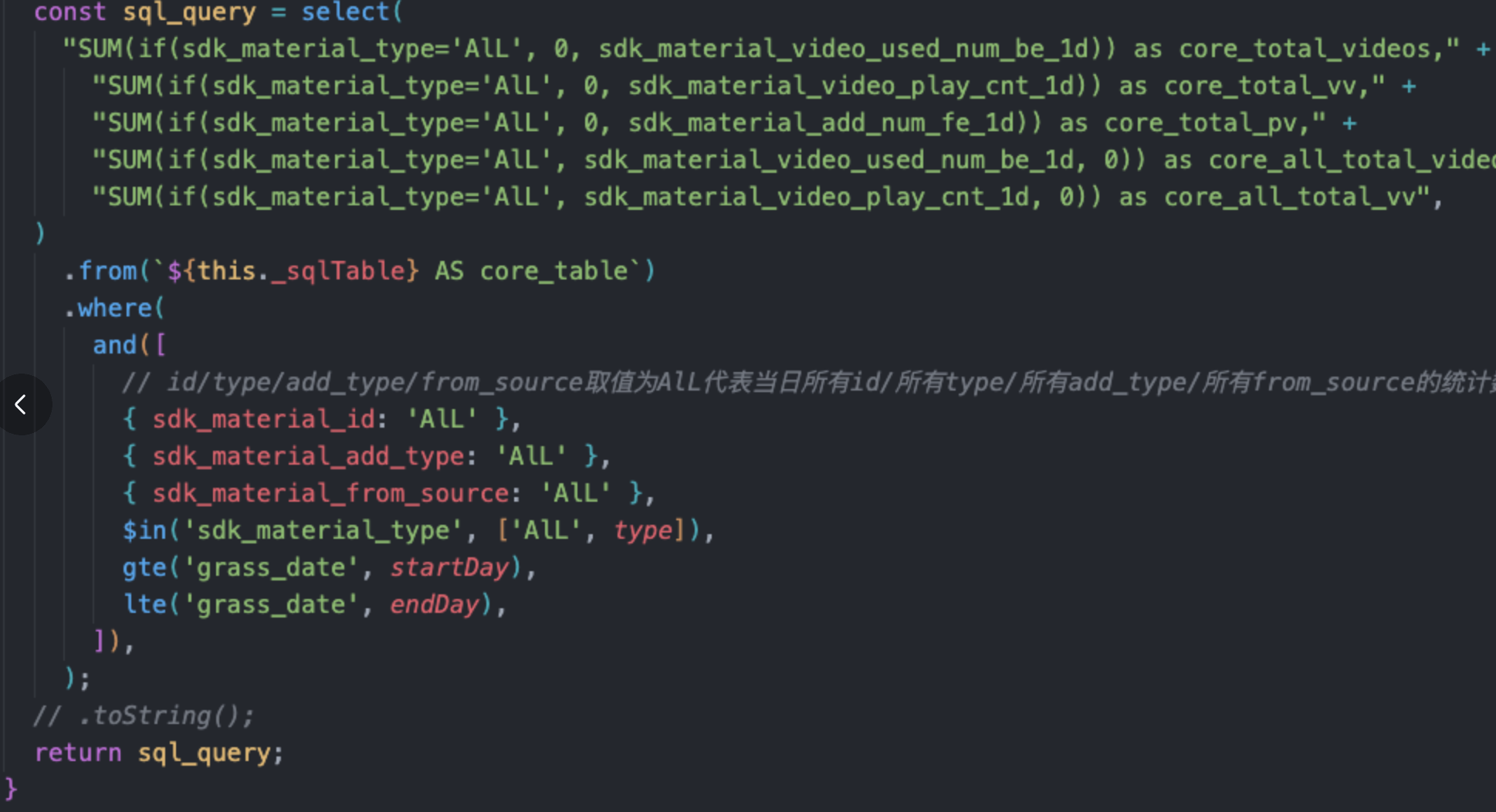
针对dataZoo这里比较大的查询SQL,咨询了服务端的处理方式,也没有太好的做法,一般就是利用orm库来减轻一些拼接sql的负担。
对于类似SUM和if()判断等求和/判断逻辑一般也是交由给SQL来做,交由给业务层,一方面要额外写聚合逻辑,另一方面如果数据量大,内存操作可能会有oom的风险。